I realized that it might be nice if you happen to stumble on this website if I had a way to recommend other websites you might enjoy. As it turns out this is a "blogroll", a concept I have never heard of before today but whatever. It's still a good idea.
I tried to add some CSS to make it easier to follow and search, but let me know if you think I missed a great site that people should check out. I'm also always on the hunt for more good stuff to read. You can find my email and social on the About page above.
Listening to two acquaintances argue about if AI art is "art" is not a new experience for me, the now eternal debate between Doomer and Boomer. In this particular context, I'm listening to it as I wait for my surprisingly expensive iced latte in downtown Copenhagen. This coffee shop is one of my favorites, a small hole in the wall where the shop starts on the second floor. Everything is hand painted in a way I associate with the hippie roots of Copenhagen. They have an older golden retriever lying on the floor in the heat with a sign on his crate telling people not to bother him if he's taking a break. "Sometimes he needs his alone time". Me fucking too I think as this conversation drags on.
There is a certain irony to the people having this conversation. One is a well-off tech worker, telling the much less well-off artist that the thing he has made through a prompt and the thing she practiced for years to make are functionally the same thing which is a classic AI Boomer argument. "I'm not saying I would sell mine, but isn't the point of art the emotion it brings out when you see it?" The artist seems somewhat baffled by the question, which I understand because she doesn't see the world as a machine that inputs ideas and outputs profit. I use some LLM tools while programming but I would argue I am still more Doomer than Boomer.
As someone who straddles these two worlds, both working for large corporations and interfacing with these borderline sociopaths in business casual pants and expensive watches and also as someone who finds the joy in their life through the celebration of the artistic output of others, I understand them both. One sees it as a capacity problem, a barrier broken down so that now he can do everything and no choices have cost. The other sees it as a baffling attack on her passion. You could always learn to draw, nothing was ever stopping you is her refrain. Which is true but doesn't resonate with him, in part because I suspect he believes he could do anything.
But I hear this argument enough that I thought we should talk about it, if for nothing else than to give me something to think about as I stare at the dog crate and hope the dog comes out to say hi.
The Smell of Ink and Nerds
So I love books of all sorts, including a lot of very trashy books. Nothing I enjoy more than a Space Marine ripping the head off an alien. One medium that I really like as an adult with limited free time are comic books. I love everything about them, the feel of the too slippery covers and the rub-off on your fingers of old comics. I love how weird they are, how stories that don't work are dropped on the floor and never mentioned again. It's like watching someone build a railroad as the train rides down the tracks.
My routine for years was to go pick up my pull list and then wander around for a bit while they assembled it. This is how I found great series like Sandman and countless others that ended up being some of my favorite reads. One of these pull list discoveries I made while standing around surrounded by the delightful acidic smell of a comic book shop was The Black Monday Murders. You can find it here.
The story of The Black Monday Murders is genius and I won't ruin it. You can read the first issue for free at the link above. My friends and I still text each other "All Hail God Mammon" when the stock market goes way up or down. The basic concept was "what if money and magic were related and banks were basically worshiping the god of greed". I consumed this series and fell in love with it.
I mean come on what's not to love about that.
So the first issue comes out in 2016, we get a....very slow drip of new releases through 2018. 2018 is when I got issue 8 and then that's it. Since then we have had teased new issues, every year or so someone posts on social media "oh there's a new one coming". There is a lot of media like this but for me, this is the one I think of most often as "what-if". I think it is a genius idea that is especially relevant in today's world and I am sad that we may never get another one.
So I was expressing this to a boomer friend who casually responded with "why don't you just make your own"? LLMs allow us to generate lots of artwork like this now, you can maybe cobble together a story, wouldn't it be fun to make your own issue for your own personal consumption? To him, this is the perfect use of this technology, allowing a fan to make more of the thing they love. To me it feels like if someone said "if you are hungry, there's a puppy over there, just pop that bad boy in the oven for 2 hours and have yourself a snack".
To me that's not a tribute or the act of a fan. It's making a forgery. The thing has no value to me as a reader if I removed it from the entire creative context of its creation.
What value does a forgery have?
There's a great short essay by the philosopher Denis Dutton from 1979 called Artistic Crimes. It's about forgeries, not AI, but every paragraph rings like a bell for the argument I keep having. You can read the entire thing here (it's not that long I promise).
What I was struck by was how many parallels you can draw between the two issues. Like AI art, the existence and occasional acceptance as real artistic works of forgeries has a special power to discredit the art critic and historian community. The success of a forgery creates a belief that the entire criteria by which art is judged by is fundamentally flawed. If something is amazing before you knew it was a fraud and trash after you came to find out it was fake, then the assessment of art has no basis in aesthetic properties. It is pointed to as a demonstration that the only reason a "masterpiece" is valued over a random painting at the flea market is that a famous person made the first one. Effectively all art is bullshit and LLM slop/forgeries are equally valid because they invoke the same emotions in the audience before the deception is revealed.
Now everyone, or at least everyone whose opinion I value, can agree that knowing if a piece of art is real of fake matters in terms of both its monetary value and its value historically. Even the most staunch Boomer I know would admit that fake paintings shouldn't hang in museums next to real ones. Where the two groups diverse, in LLM art and forgeries, is whether the assessment of its aesthetic merits should not be impacted by its status as real or fake.
Part of what is impressive about the performance of making something is that you are celebrating how much a person or group of people succeeded. This is why we delight in stories like "Stardew Valley was made by one person in his house for years with no money hand-drawing each piece of art in the game, so intense was his love and commitment to the project". You don't have to know that to enjoy the game, but pretending it changes nothing about how you enjoy it once you do it is nonsense. Same with movies like "Good Will Hunting". Sure it's a good movie, but the story of two childhood friends making it for not a lot of money and one of them leaving Harvard to shoot it changes your connection to the material. It can't not. You love the thing, you learn more about the human story behind the thing, you love the thing even more.
Part of the magic of wandering through a museum is that I cannot do the things the artists here have done. I cannot make modern art, I don't have a vision like those people do. I don't have the strength of character and conviction to commit to something like they do. I frankly lack the fucking spine to stand there next to a creation of mine that a thousand morons a day will look at and say "I could do that". No you couldn't and that's part of why its impressive to look at.
Forgeries, like LLM art, are misrepresentations of achievement. You want the same credit and respect as someone who actually did a thing, but you haven't done the thing. Once that discovery is made or, frankly, one that is suspected, the relationship to the work has been permanently changed. I'm no longer viewing it from the perspective of the output of a human who I want to succeed but instead skeptically as someone attempting to steal credit for work they didn't do.
The question of efficiency
The other argument the boomers make is about bottlenecks. My favorite comic isn't finished because the author is busy and human. But we could feed the machine the premise, let it crank out pages, have him touch them up, and, bim bam boom issue nine, ten, eleven, a hundred.
Let me be clear that I'm not precious about everything in my life. I am not one of those people who thinks everything must be handmade by candlelight. I love a Dunkin Donuts coffee. I love the ridiculous bucket-sized cup, the sugar content that could kill a horse, the milk-adjacent liquid that has clearly never seen the inside of a cow and is shelf-stable until the heat death of the universe. I love standing in line behind two guys in Carhartts complaining about a foreman named Chris who is, and I quote, "a real fucking prick, man." I could eavesdrop in an IHOP for the rest of my natural life and die happy.
Sometimes I want the $22 burger. Sometimes I want the McDonald's cheeseburger, no pickles. Both are fine. Both have their place.
But here's the thing the boomers keep missing: I get to pick.
The choice is the thing. And the AI rollout, as currently constructed, is designed to remove the choice. Not offer a new option but replace the existing one. The boomer argument, stripped of its language about productivity and democratization, is really this: we're going to make the cheaper thing, we're going to stop labeling it, and you're going to keep paying the same price because what are you going to do, not consume media?
Because it is cheaper and faster to make doesn't make it something anybody wants. My favorite local bakery makes a great sourdough that I try to get whenever I can. If they sell out, I don't buy a loaf of Wonder Bread and pretend it's the same thing. I go home without bread. Sometimes the honest answer to scarcity is going without.
This is what boomers can't hear. They think we're arguing about the quality of the output, and so they keep showing us better and better outputs as if that will close the deal. But we're not arguing about the output. We're arguing about what it means to receive a made thing from another human being. Every comic in my pull list, every trashy Space Marine novel, every weird indie game are letters from strangers who cared enough to spend years of their lives making something for me to find. The value isn't in the artifact. The value is in the fact that somebody bothered.
A machine cannot bother. It can only produce.
I would rather have eight issues of The Black Monday Murders and the ache of never getting a ninth than a thousand AI-generated issues that continue the story forever. The ache is part of the art. The waiting is part of the art. The possibility that the thing I love might never be finished is part of what makes it real. Forgeries don't ache. They just fill space, like the paintings in a Best Western lobby, hung there because a wall needed something on it.
All hail God Mammon. He always did prefer the cheaper option.
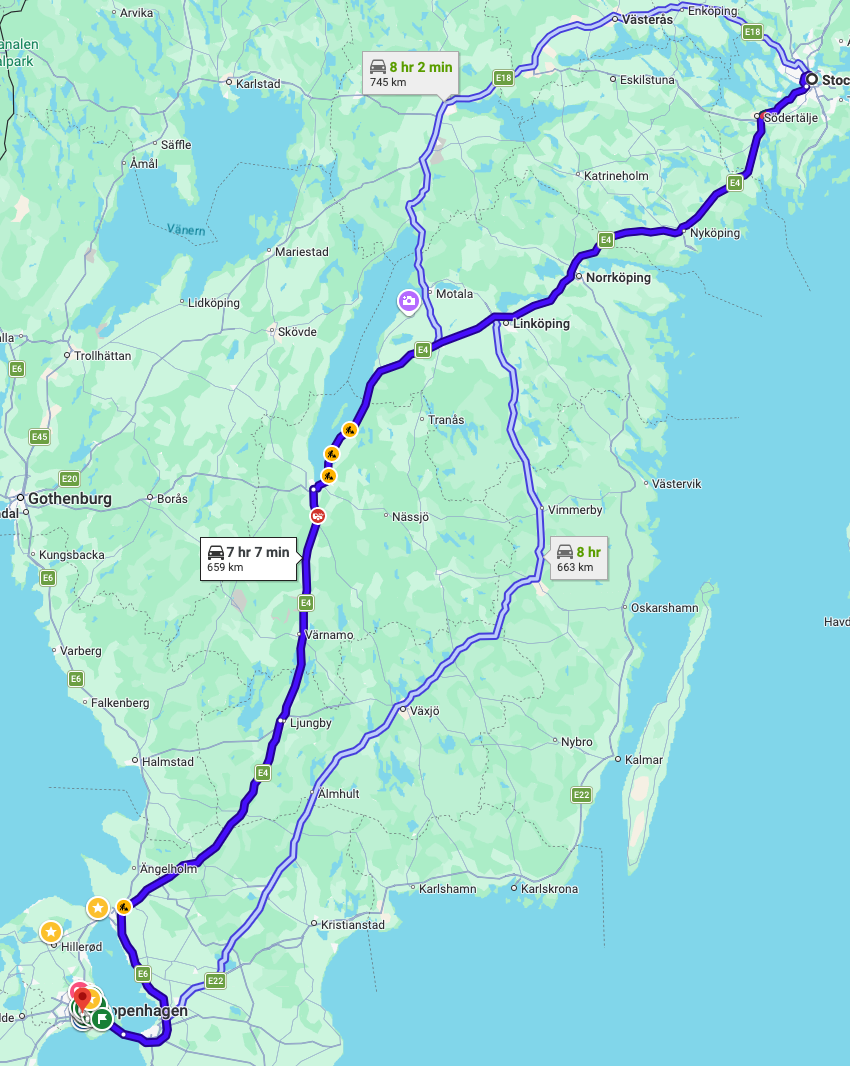
I was recently summoned to a meeting in Stockholm, a city I had somehow managed to avoid despite living in Copenhagen for years. My Swedish experience, up to this point, consisted entirely of trips to Malmö — the closest Swedish city to Denmark and, more importantly, home to a Costco. As an American living abroad, I am duty-bound to report there every six months so the proper authorities know I'm still alive and to procure my ceremonial barrel of peanut butter pretzels. It's less a shopping trip than a consular check-in.
Stockholm, it turns out, is much further from Copenhagen than anyone lets on. My options were to fly or take the train. Flying is technically a one-hour affair, but to make a 9 AM meeting I'd have to wake up at 4 AM, shuffle through security in a fugue state, and land in Sweden looking like a hostage video. I wasn't sure when I'd nap. This seemed insane.
Then I had what I believed, at the time, to be a genius idea: the overnight train from Malmö to Stockholm. I'd sleep en route, wake refreshed, stride into my meeting like a man who understood something about life that others did not. Plus, I love trains. Sweden has a high-speed line that does the run in four hours, but the night train takes its time, which sounded charming. It was not charming.
The first surprise came at booking. There are three tiers of experience: a seat, a couchette (whatever the fuck that is), or a private sleeping compartment. Since I wasn't paying, I chose the private compartment. This would prove to be the single smartest decision of my adult life, possibly of anyone's adult life. If you are reading this from some point in the future and you are over the age of thirty, book the private compartment. I don't care what it costs. Sell a kidney. I'll explain.
Departure
My train left Malmö at 10:30 PM. The station there is depressing in a way that's hard to articulate in that nothing is obviously wrong. There's a grocery store. There's a convenience store. And yet everyone inside looks stranded, as though they've been waiting for something that isn't coming. Small children roam in feral packs. There is a pervasive sense that this is the last train out of somewhere very bad, and that whatever is chasing everyone is still, perhaps, on its way.
Amtrak in the US has this feeling, a vibe that you are running from the law. I remember when my family used to take the train from Ohio to New Jersey, waiting for it at a train station that was basically a concrete bunker in the middle of a corn field. The concrete box would either be freezing cold due to too much AC or boiling hot due to too much heat. I would stay up late on the train and watch as parents would abandon sleeping children to jump off at stops and catch a smoke. They all had a nervous desperation that these Swedish travelers shared. It's the kind of place where you wouldn't be surprised to see someone take a SIM card out of a phone and throw it in the trash.
I stopped at the grocery store and loaded my backpack — my only luggage — with provisions: two large water bottles, wet wipes, a change of clothes, a bag of nuts, and, as an emergency measure, two Red Bulls, in case sleep failed me and I had to power through the following day on hatred and that cursed, faintly urine-themed energy drink. Then I stopped by the men's room, which featured a decorative fish tank whose sole occupant had a full-frontal view of the urinals. If reincarnation is real, Henry Kissinger is in that tank.
European train station bathrooms are often weird, but this was up there. First there was no automated system to get in, it was just a guy with a credit card reader. Also they were piping in tropical sounds to the bathroom which I assume is to cover the unspeakable horrors happening in the stalls. I felt uncomfortable that I kept looking at the fish and found it to be always staring at me. The tank was in really good condition, with incredibly clean water. I couldn't help but think maybe its better for the fish to die faster than live their entire lives staring at an endless line of men peeing.
I found my train and boarded, and I knew immediately I was in trouble.
This was an old-school train — varnished wood, worn blue upholstery, late-70s energy throughout. The regular seats were hard, upright benches with little fold-down wooden tray tables. They did not recline. Not a little. Not at all. Which raises the question: why call it a night train? Night train implies, to me, that at some point during the night, someone might sleep. But the seats also had bright lights above them that never turned off, which transformed them from sleeper seats into something closer to interrogation chairs.
The couchettes turned out to be stacked bunks — men-only, women-only, or mixed and the passengers were packed together so tightly that the gender segregation began to make a grim, practical sense. I'm not squeamish around strangers, but we're talking well within reach-out-and-stroke-someone's-hair range. My private room looked roughly like a jail cell: a cot, a light that turned off, a door that locked. In other words, everything I have ever wanted from a hotel. That's not sarcasm, I'm easy to please.
Naturally, I was far too curious about the rest of the train to actually sleep, so I set out to wander.
Train to Hell
The three conductors on duty were all wearing bodycams strapped to their chests, which is always an encouraging sign in that it suggests both that they had been attacked and that they had, at some point, done some attacking of their own. They were also wearing shorts, which felt deeply wrong. There's something unsettling about a train conductor without pants. It's a formal job. You don't want your pilot in flip-flops and you don't want your conductor showing knee.
I don't know what it is about shorts on men specifically that come across as clownish, but there is a ranking of jobs where one shouldn't wear shorts all the way to one cannot wear shorts. Doctors, pilots, lawyers, accountants are all pants jobs. Train conductor felt like a no-brainer that it would be a pants job, also frankly I think they should also have to wear a cool hat and have a pocket watch. In the same way I would bristle at a judge sentencing me to death in a Hawaiian shirt, a train conductor in shorts checking my ticket feels wrong.
I made my way a few cars down to see how the general population was faring.
The door slid open and I was hit, physically, by the smell of cheap vodka. Before me stretched a sea of Swedes, each with the specific facial expression of a person who has just realized they have made a terrible mistake and cannot un-make it. Two people were openly weeping. Three others were borderline-homeless-looking punk kids dressed exactly the way punks dressed in 1994 — I don't know who is still manufacturing M65 field jackets and military jump boots, but they're clearly still moving units in southern Sweden.
One of the punks was vomiting into a plastic bag, seated next to a very sweet-looking, deeply concerned young woman who had presumably boarded this train with hopes and plans. She had the look of a woman who had her life together. The conductors arrived, spoke to him, were told to fuck off, and then quietly relocated the young woman to a new seat the way you'd move a house plant away from a leaking radiator. The punks then began joking loudly among themselves, two of them taking turns retching up what smelled like vodka cut with unleaded gasoline.
God help anyone trying to sleep back here. Between the puking, the reek, and the punks openly hitting on every woman within shouting distance, it was like being trapped on a Greyhound bus that had sworn a blood oath never to stop. I watched a man roughly my own age attempt to sleep by laying his face directly on the wooden tray table, earplugs jammed in, arms limp at his sides, in the international posture of I have given up.
I left when a boyfriend and girlfriend began fighting because she had proven surprisingly receptive to the advances of a punk kid whose body odor was strong enough to reach me three rows back. The boyfriend — sitting directly next to her — took issue with this, which seemed reasonable. I moved on to the meal car.
The meal car was the hangout, the refugee camp, the place where people who had discovered they couldn't sleep in the bunks came to sit and stare into the middle distance. Two young women were seated at a table nearby, one of them work-shopping, in English, why she deserved better than her current boyfriend in Malmö.
"I don't think I should settle for average."
Her friend was being supportive and kept trying to inject something about her own life, only to be steamrolled every time.
"Yeah, I know exact—"
"It's just, I work so hard at school and he doesn't."
"My last boyfr—"
"Maybe when we get to Stockholm we go buy some nice dresses and go dancing."
"That sounds fu—"
"Because I really do think I deserve to feel beautiful."
After a few rounds of this, I got bored. It was all early-twenties drama, and I don't say that with contempt because it's a phase we all pass through. In your twenties, you discuss your plans and feelings as though they matter, because to you, they do. In your late thirties, you come to understand that nobody actually cares if you live or die, and you learn, mercifully, to keep it all to yourself. It's one of the small gifts of aging, along with knowing how to fold a fitted sheet and no longer pretending to enjoy helping people move.
Friends in your 20s are your therapists, your closest confidants and your relationship counselors. In your 30s, you have an actual therapist and don't have to burden the people around you. At some point in everyone's life someone they love and respect will put up their hands and say "alright ENOUGH" and you'll realize how tiring you are. These women hadn't gotten there yet, but I did think the friend should start charging for this therapy session.
I retired to my cabin and fell asleep almost instantly. The rocking of the train, the smug satisfaction of not being propped upright in a wooden pew next to a vomiting stranger, and a modest dose of melatonin combined into something close to bliss.
Stockholm
We arrived on time. I grabbed my backpack and stepped out into Stockholm Central Station at 6 AM, which was nearly deserted. I found a coffee shop, ordered a coffee, and was charged an amount that made me wonder "should I open a coffee shop in Stockholm?". As he handed it over, the barista said, cheerfully, "It's my first day."
"You shouldn't tell people that," I replied.
I then felt terrible about it for approximately one hour. He, for his part, seemed entirely unfazed, or possibly hadn't heard me at all, which somehow made it worse. I carried the guilt with me through security, out onto the street, and into the cab I hailed for the twenty-minute ride to my meeting.
The meter began climbing almost immediately, and with a kind of enthusiasm I hadn't previously known meters possessed. He asked where I was from. I said the U.S. He said he loved Americans. He said Americans were the best people which, frankly, nobody says unless they're being tortured by us. He asked if this was my first time in Stockholm. He asked what I did for work. Every question was warm and generous and I understood, dimly, that I was being courted.
But it was only twenty minutes, how bad could it be? Eleven hundred kronor later, I stepped out onto the curb while he tried to press his business card into my hand so I could call him directly for future rides. Having just paid roughly $120 to travel the distance of a decent jog, I now understood his enthusiasm. He'd hit the jackpot, and the jackpot was me.
The meeting wrapped in a few hours. I took an Uber back for a quarter of the cab fare — a small, petty vindication I savored the entire ride — and spent the next four hours walking around Stockholm. It's genuinely lovely, and denser than I expected. Copenhagen feels like a city that was designed by someone who liked people; Stockholm feels like a city that was designed by someone who respected them but wasn't sure he wanted them over for dinner. More cars, less green, wider streets, harder edges. Every Swede I passed looked as though they were on their way to something slightly more important than what I was doing. It was beautiful in the way certain people are beautiful — the kind of beauty that doesn't especially need you to notice.
Conclusion
Should you take the overnight Swedish train? Honestly? Probably not this one, unless you are terrified of flying or being sober. The only tolerable option for an adult human is the private cabin, and at that price you can usually just fly. But it was, undeniably, an experience and one I would happily repeat, provided someone else were footing the bill.
For roughly the last ten years, a meaningful percentage of my working hours have been spent thinking about observability. If you're not familiar with the term, "observability" is what we call it now that "monitoring" doesn't sound expensive enough. The actual work is unglamorous in that you collect a lot of logs, some metrics, a few traces, and then you give them to people.
I generally like my job. I like that we're always trying new ideas and approaches. I like the fact that when things go wrong, the answer is almost always sitting there in the data, waiting to be found by whoever is patient enough to look. But I want to be honest with you: in ten years of doing this work, across a half-dozen companies and every observability platform you've heard of and a few you probably haven't, logs have never stopped being the worst part of the job. They were the worst part when I started. They are the worst part today. I fully expect them to be the worst part of this job forever until the robots rise up and rip my head off in one clean sweep.
I've written about why logs are terrible before, so I'll spare you the full lecture and give you the short version.
Every developer's expectations for logs are set by a single formative experience: the syslog box. Or a container running locally. Or tail -f on a production server they probably shouldn't have SSH'd into. The point is that at some early, tender moment in their career, they had an experience with logs that was flawless. They ran grep and something useful came back. They piped it into jq and got exactly what they needed.
This experience is the observability equivalent of a first kiss. It ruins them for everything that comes after.
Because here is the thing about that flawless experience: it works because the system is small, the volume is trivial, and the person querying is the same person who wrote the log line. There is no schema drift, no cardinality explosion, no cross-team consumer with dashboard expectations, no VP asking why the "revenue events" graph has a gap in it.
Then there are forty services. Now there are four hundred. Now the logs are being consumed not just by developers but by customer service, who need to look up a specific user's failed checkout from Tuesday. And by the data team, who are quietly building a business-critical dashboard on top of a log line that a backend engineer is about to refactor without telling anyone. And by the on-call, who at 3 AM does not want to learn a new query language, does not want to think about index patterns, and would like the search bar to just work.
So you have a technical problem — the volume is enormous, the shape is inconsistent, the queries are unpredictable — sitting on top of an expectations problem, which is worse. Developers want logs instantly, they want to run arbitrary operations on them, and they will not commit to a schema. Meanwhile the less-technical consumers of that same data want the dashboards to be stable forever, the UI to be forgiving, and the whole thing to feel like a normal product. These two audiences are, in most practical respects, at war with each other, and you are the diplomat.
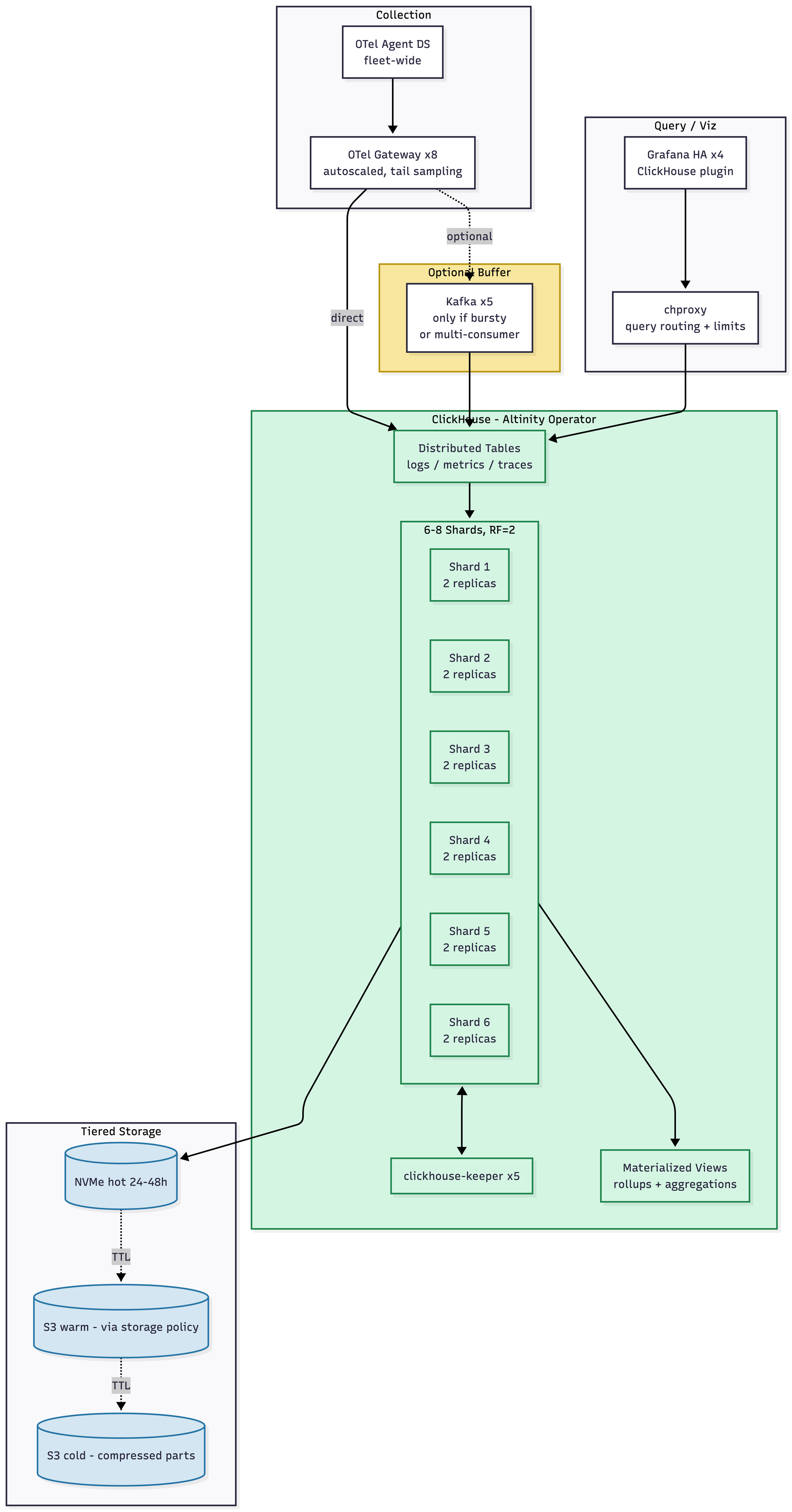
Clickhouse
ClickHouse came out of Yandex, where it was built to chew through analytical queries against absurd volumes of clickstream data. It was not designed for observability. It just happens to be shockingly good at it, because clickstream data and observability data have a lot in common: high volume, append-heavy, time-ordered, mostly read in aggregate, and every so often you need to reach in and find one specific needle.
You can run it yourself with Helm charts. You can point Grafana at it via the ClickHouse plugin, or use their own web UI, or bring your own frontend. Their docs are actually good, which I mention because it's rare enough to be worth flagging. I've never used their ClickStack setup though, so YMMV.
For observability specifically, the OpenTelemetry Collector has a ClickHouse exporter, which means you can pipe OTLP data straight in and let it manage the initial schema for you. ClickHouse is designed to scan billions of rows and ingest an amount of data that, when you first see the numbers, makes you assume they're lying. They're not lying. You query it with SQL, which is a language that already exists and was not created by a startup two weeks ago.
But why Clickhouse specifically for logs?
I'm ranting about logs and then I'm explaining why I like to administer Clickhouse more. Let me take a second and explain why Clickhouse is really good at logs at scale.
Logs, as a data shape, have some peculiar properties. They're append-only. You never update a log line, and you almost never delete a single one, though you delete a lot of them at once when retention kicks in. They arrive roughly in time order, though never actually in order. They're read in bursts where nobody looks at logs for days, and then during an incident somebody wants to scan a billion of them in seconds. They're highly compressible, because most of the bytes in your logs are repeated: the same service names, the same hostnames, the same error strings, the same JSON keys, over and over and over again. And critically, when you query them, you almost always want either a narrow time range across all fields or an aggregation across a wide time range with a few filters. You very rarely want "give me one specific row by ID" the way you would from a transactional database. (There are exceptions when its something like GDPR or compliance logging which is its own subgenre of nightmares).
In a row-oriented database — Elasticsearch, Postgres, MySQL — the data for a single log line is stored together on disk. If your log has 40 fields and your query only cares about 3 of them, tough luck, you're reading all 40 from disk anyway. The database will filter it in memory, but the disk I/O has already happened.
ClickHouse stores each column separately. If your query says SELECT service, status_code, count() FROM logs WHERE timestamp > now() - INTERVAL 1 HOUR GROUP BY service, status_code, ClickHouse reads exactly three columns off disk: timestamp, service, and status_code. The other 37 columns in your schema might as well not exist. On observability data, where you often have dozens of attributes but any given query touches three or four, this is the difference between scanning 800GB and scanning 40GB.
This is also why the compression numbers look absurd. Columnar data compresses far better than row-oriented data because the values within a single column are, by nature, similar to each other. A column of service_name values might have a hundred distinct strings across a billion rows. ZSTD eats that for breakfast. You'll routinely see 10–14x compression ratios on real observability data, compared to 2–3x for Elasticsearch.
That's not the amazing part though
The amazing thing is that ClickHouse scales without changing shape.
I don't know how else to say this. Every other observability backend I've worked with mutates as it grows. The architecture at 1 TB a day and the architecture at 10 TB a day are recognizably different systems, with different failure modes, different ops burdens, and different mental models. ClickHouse at 10 TB a day looks like ClickHouse at 1 TB a day with more shards. That's it. That's the pitch. That's the whole reason I'm writing this.
Let me show you what I mean.
1 TB a Day
At 1 TB a day, every modern observability stack is roughly okay. If you're at this scale, you can pick almost anything and be productive. The differences below are real but they're not yet painful.
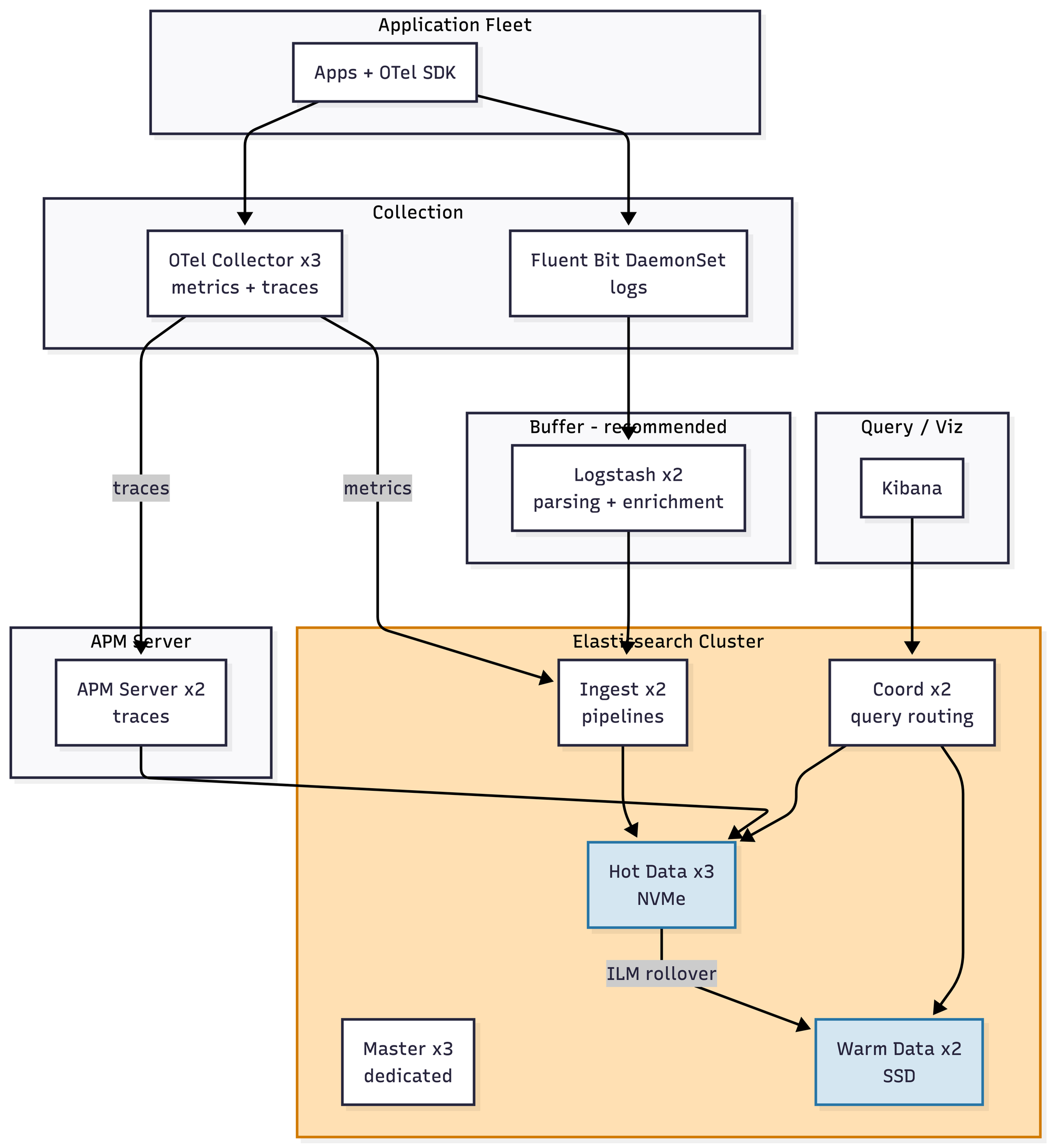
Elasticsearch
A relatively vanilla Elasticsearch cluster with Logstash providing some buffer between ingest and the Lucene indexes. Users get full-text search, which is genuinely good — this is the thing Elasticsearch is actually best at, and at this scale it delivers. Mapping explosions are already a background risk with mixed data, so dynamic mapping needs to be disabled or carefully templated from day one. ILM policies (hot → warm → delete) are non-optional even at this size, because forgetting to set them is how you get paged on a Saturday about disk pressure. Roughly $6–9K/month.
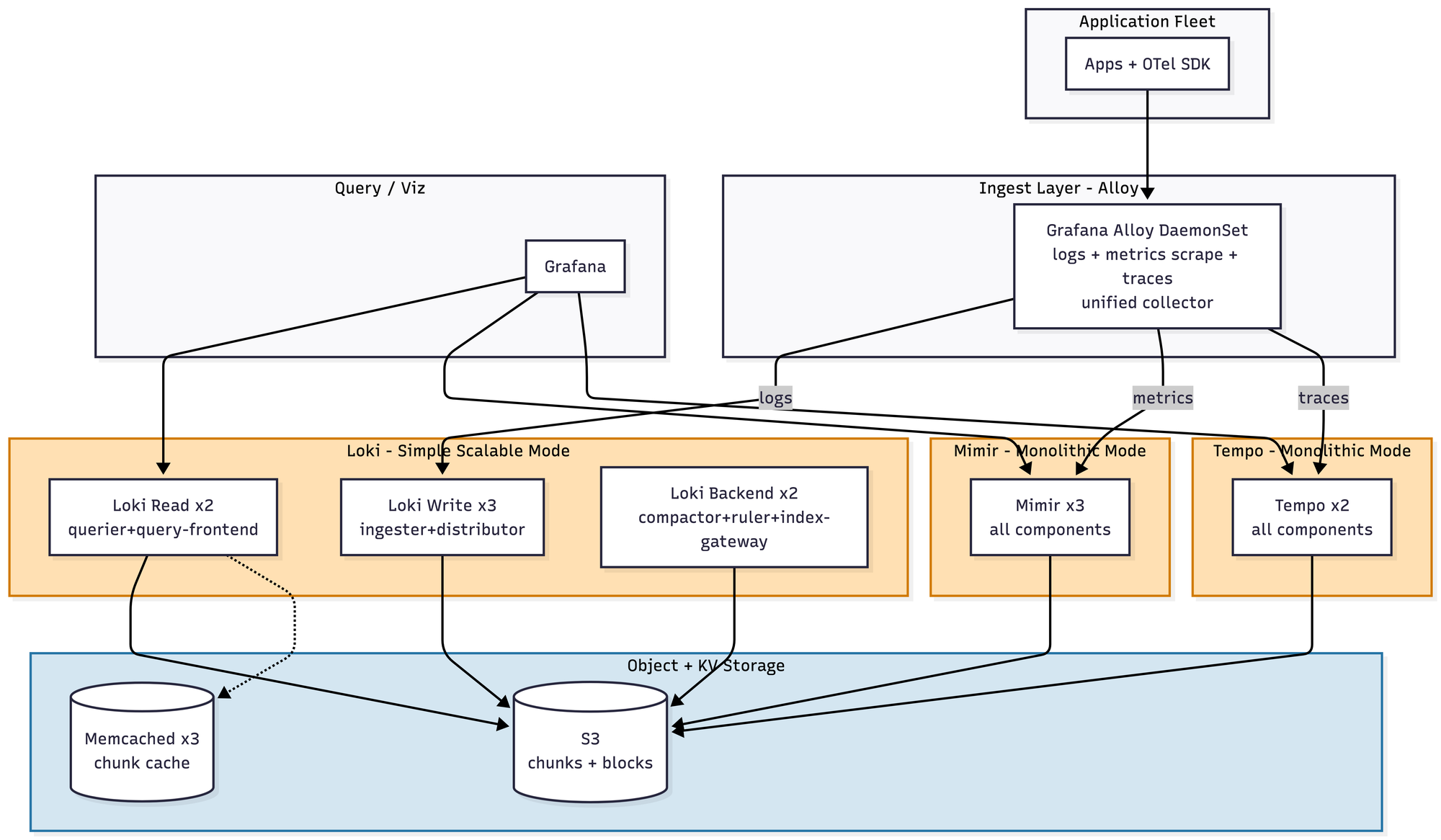
LGTM
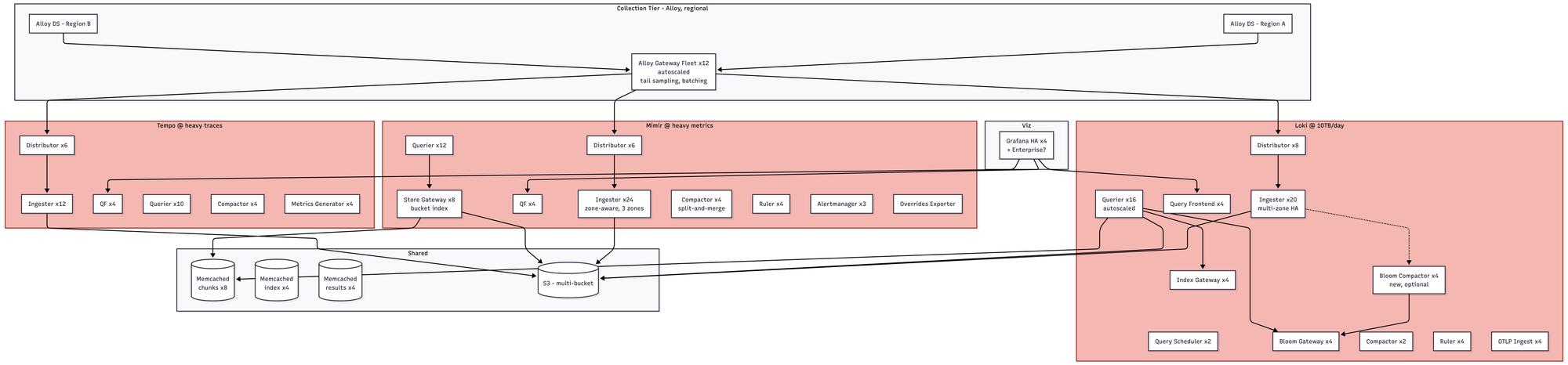
Nothing too crazy. Alloy (formerly Grafana Agent, RIP) unifies the collection story into a single daemon, which is nice. Loki works well as long as you spend some time educating developers on how to attach useful labels — a conversation you will have many times, with many people, for the rest of your career. Mimir and Tempo largely do what it says on the tin. Roughly $3.5–5K/month.
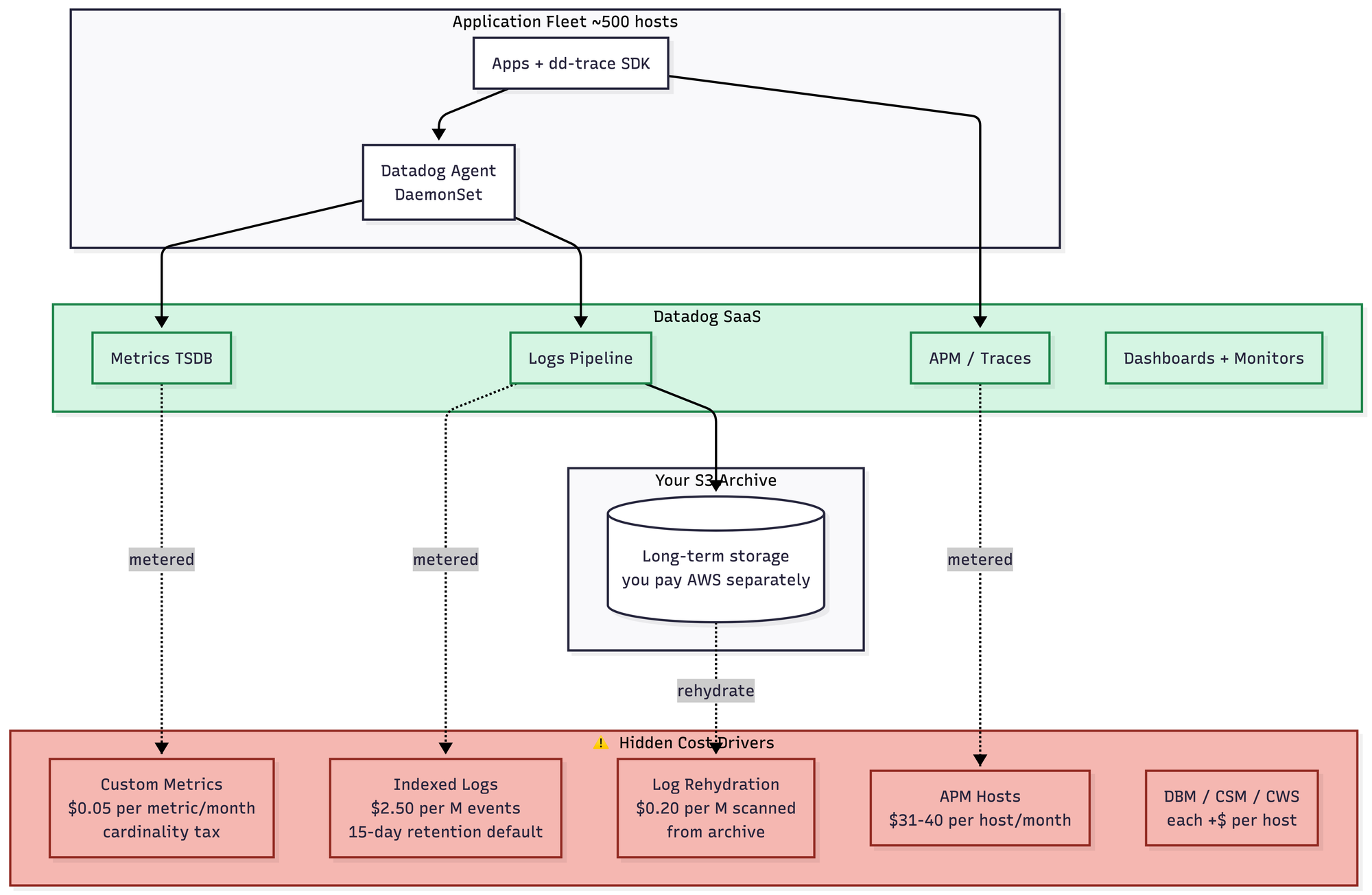
Datadog
At 1 TB a day, Datadog is genuinely great. This is the scale it was built for, and it shows. You install the agent, you look at dashboards, you go home. There is almost nothing to think about, which is the entire point. You can already see the shape of the cost problem lurking in the diagram — the metered pipelines, the indexed-vs-ingested logs distinction, the custom metrics cardinality tax — but at this scale it's manageable. Roughly $45–75K/month, though negotiated pricing varies enough that I'd take that number with a grain of salt the size of a fist.
Datadog's whole pricing philosophy is that they save you a full-time engineer. I think that framing is somewhat deranged, but they are extremely rich and I am not, so consider your source.
Clickhouse
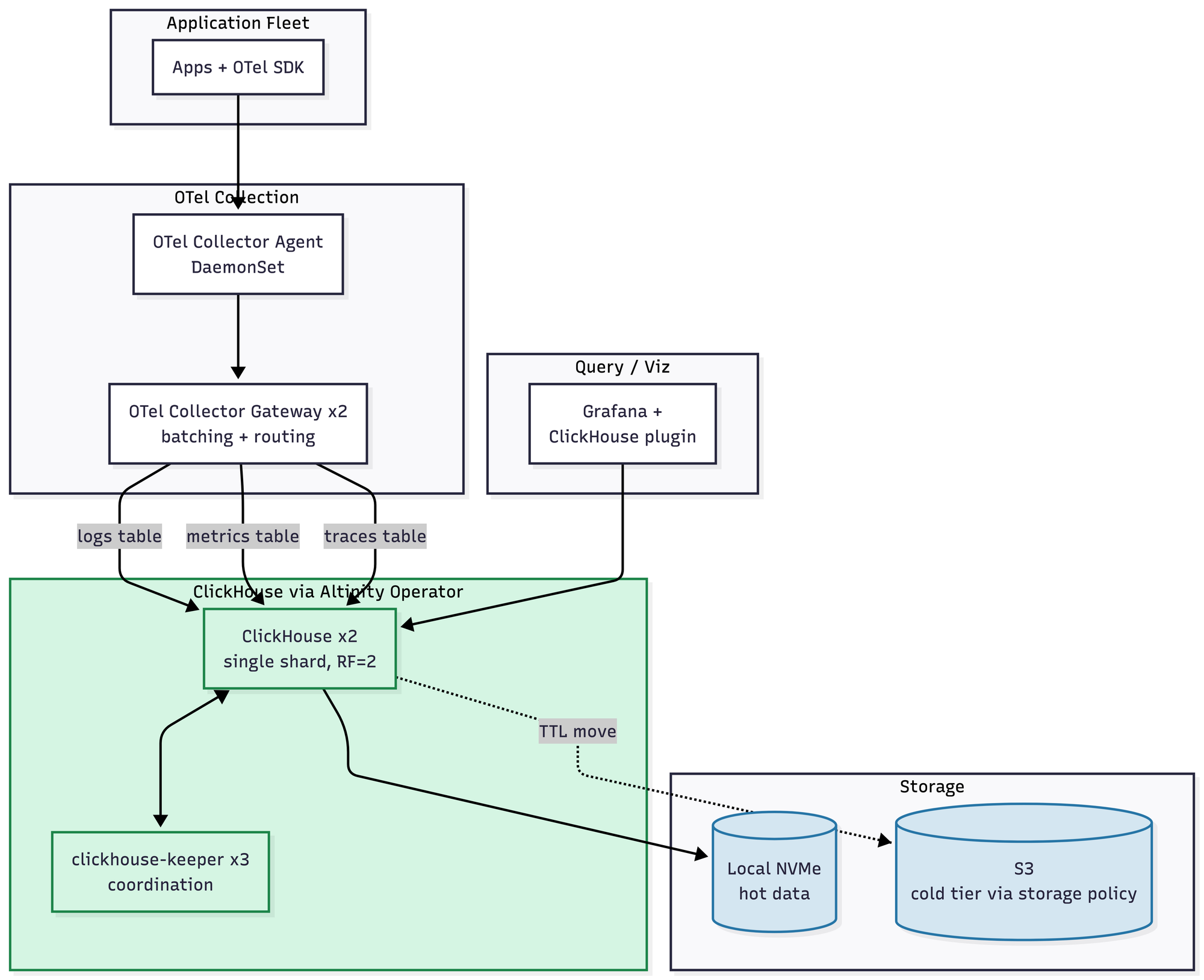
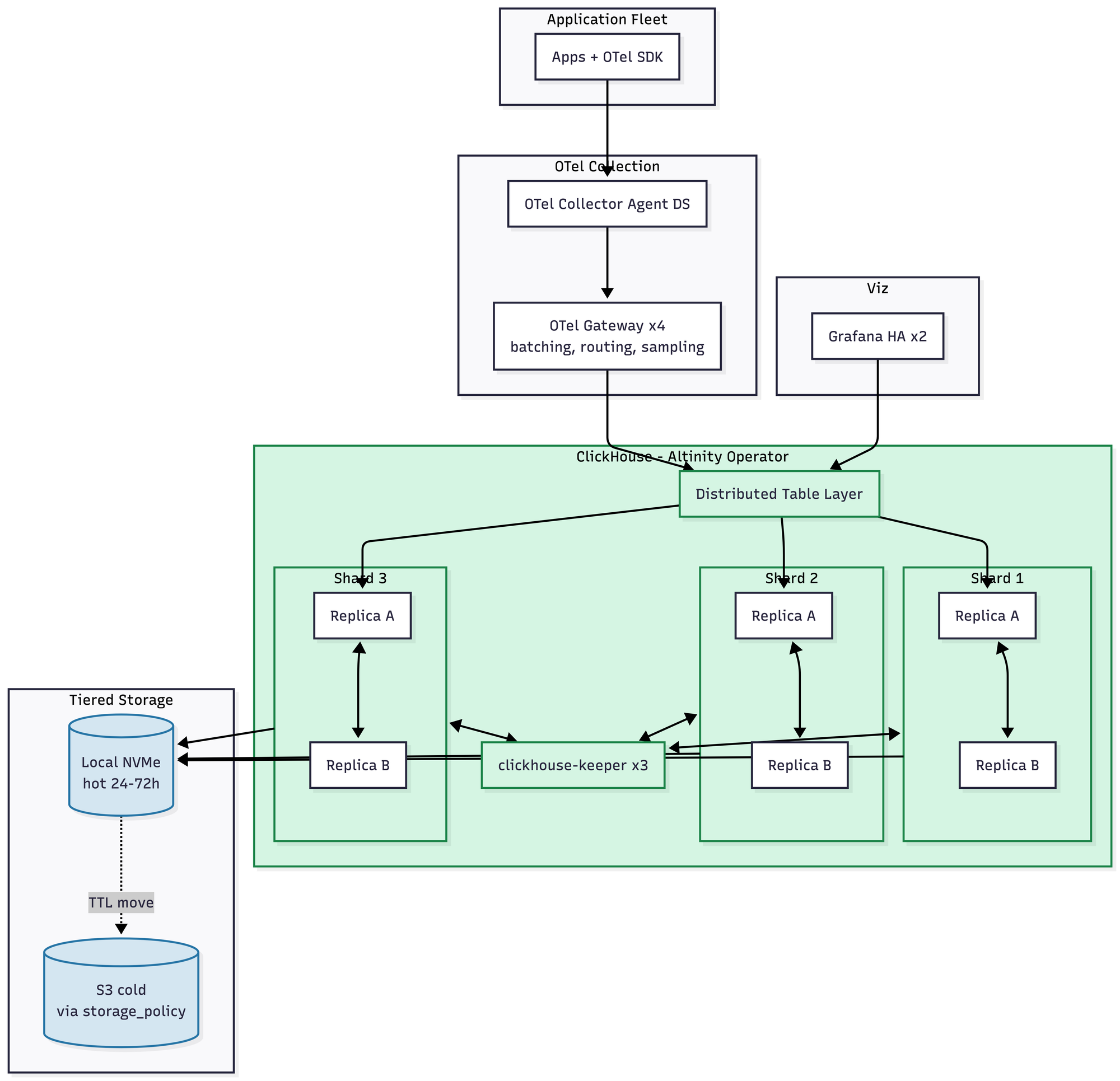
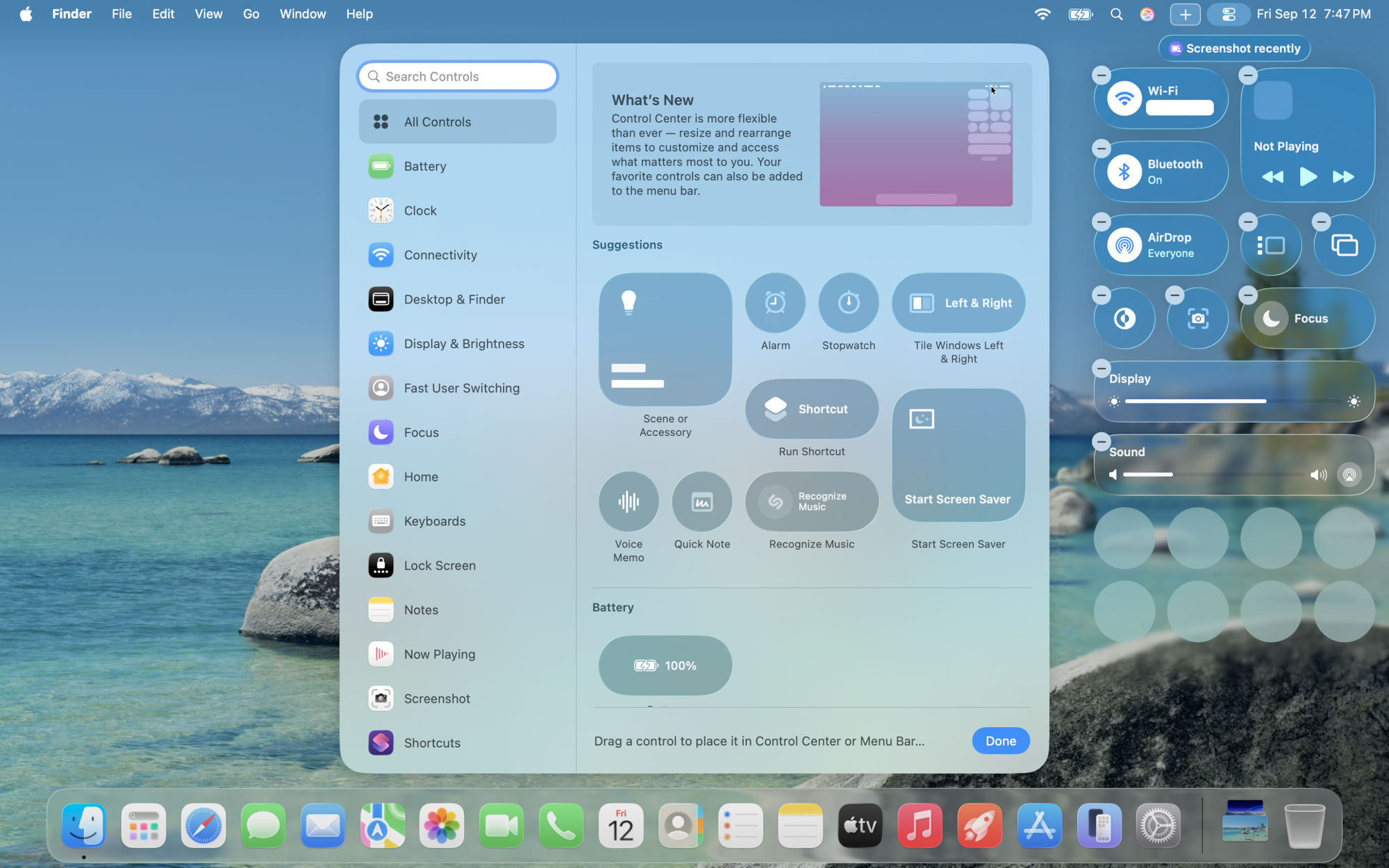
Here is the honest truth: at 1 TB a day, ClickHouse is not less complicated than its peers. It's roughly the same. Maybe slightly more, if you count the schema design work you have to do up front. You get 10–14x compression with ZSTD and proper codecs, the Altinity Operator handles keeper coordination and the whole thing runs in about seven pods. But you do have to design your schemas. ORDER BY keys matter enormously. There is no native PromQL, so metrics workflows go through the Grafana plugin or through chproxy and an adapter. Roughly $1.5–2.5K/month.
If you took the diagrams at this tier and squinted, you'd say they're all in the same weight class. And you'd be right. Now watch what happens next.
5 TB a Day
This is where the exponential curve kicks in for everybody except one of these.
Elasticsearch
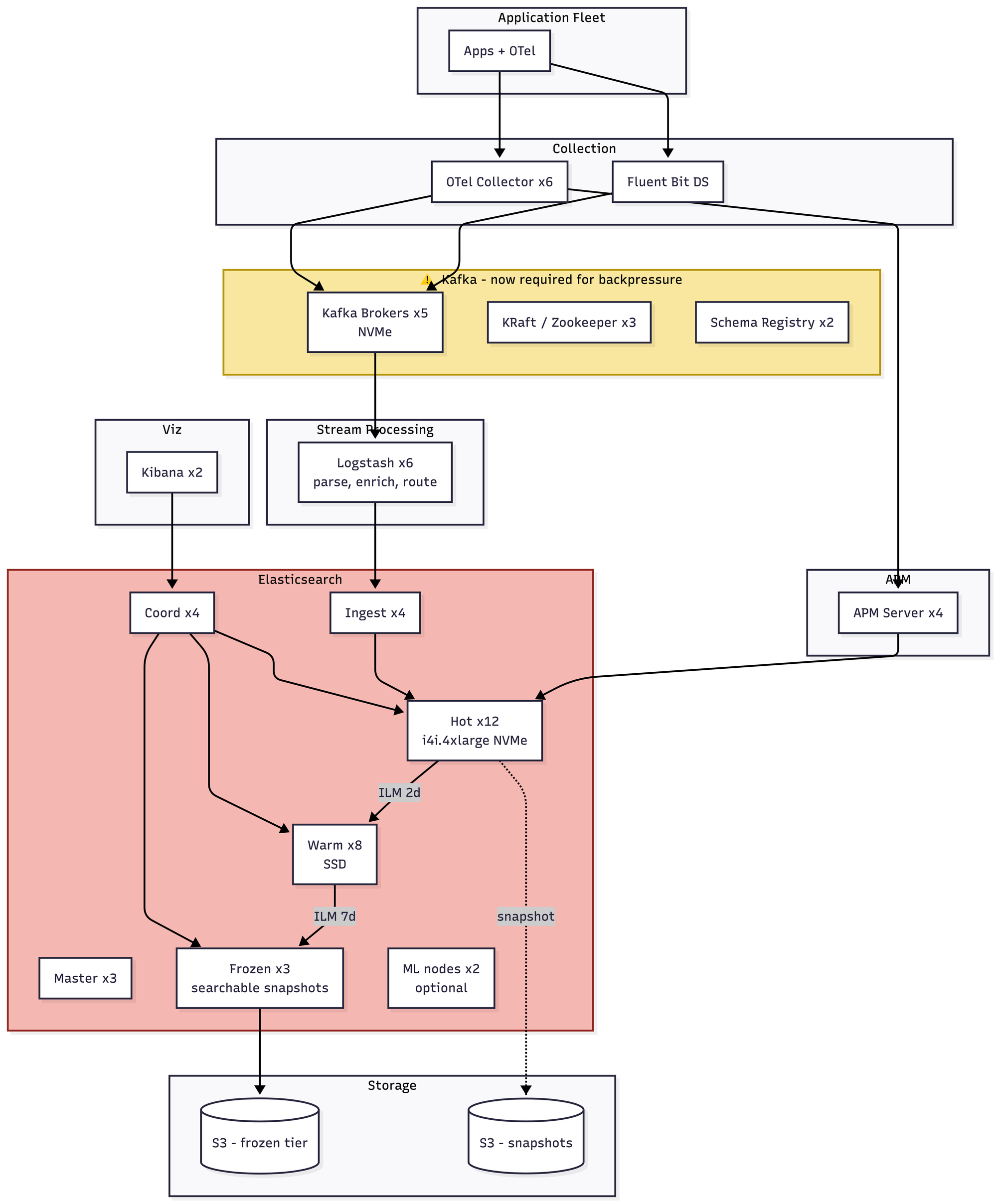
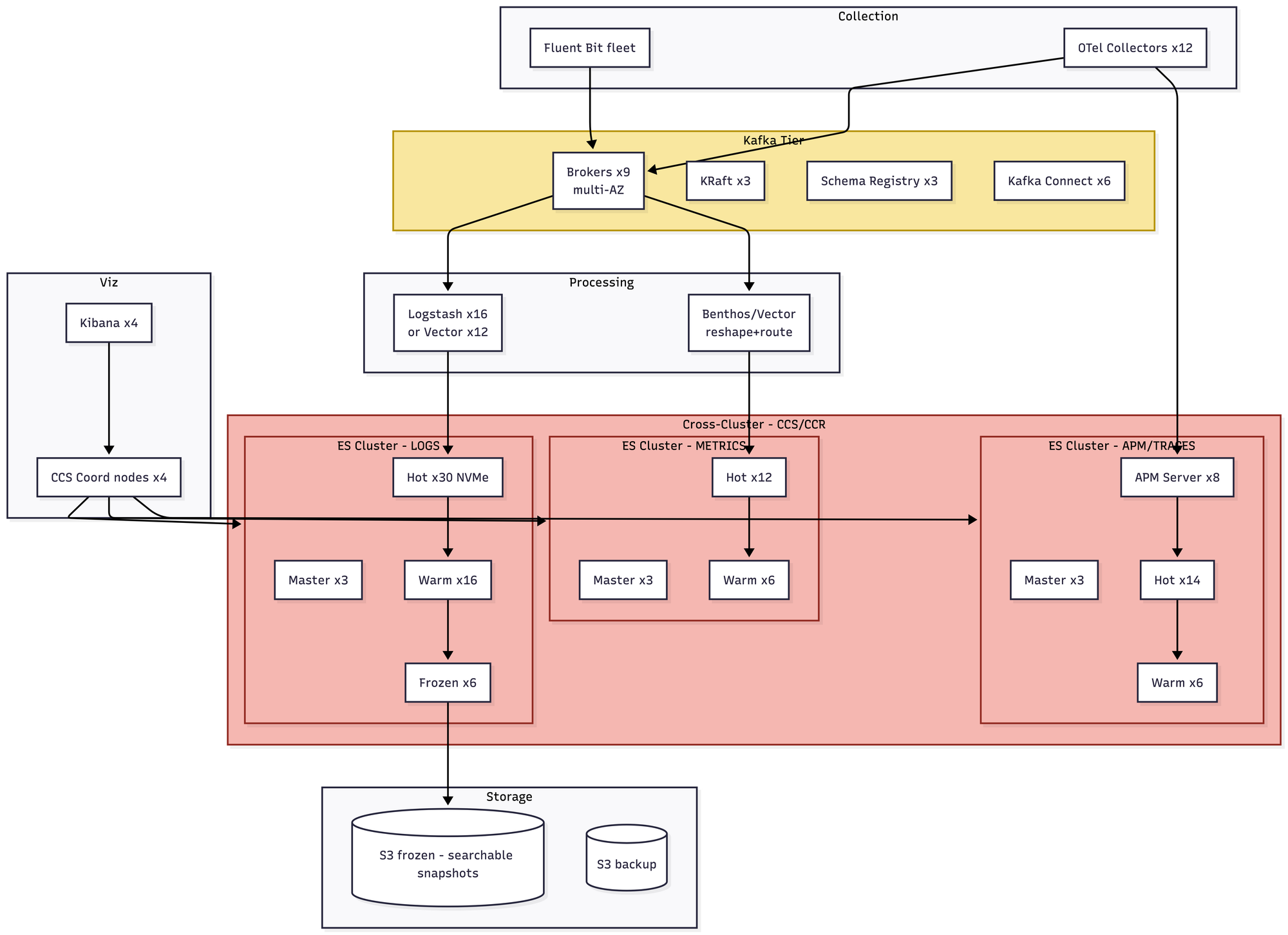
Kafka is no longer optional. At 5 TB a day, direct writes into Elasticsearch cause bulk-reject storms and backpressure that will absolutely take your cluster down during a traffic spike. So now you're running Kafka, which means you're either running Kafka well or you're about to have a second, entirely different set of problems. Shard math becomes critical — at 50GB target shards, you're minting ~200 shards a day counting replicas, and your cluster state size becomes its own concern. You almost certainly need Elastic's commercial license for searchable snapshots and the frozen tier. Roughly $40–55K/month before licensing.
That but Kafka
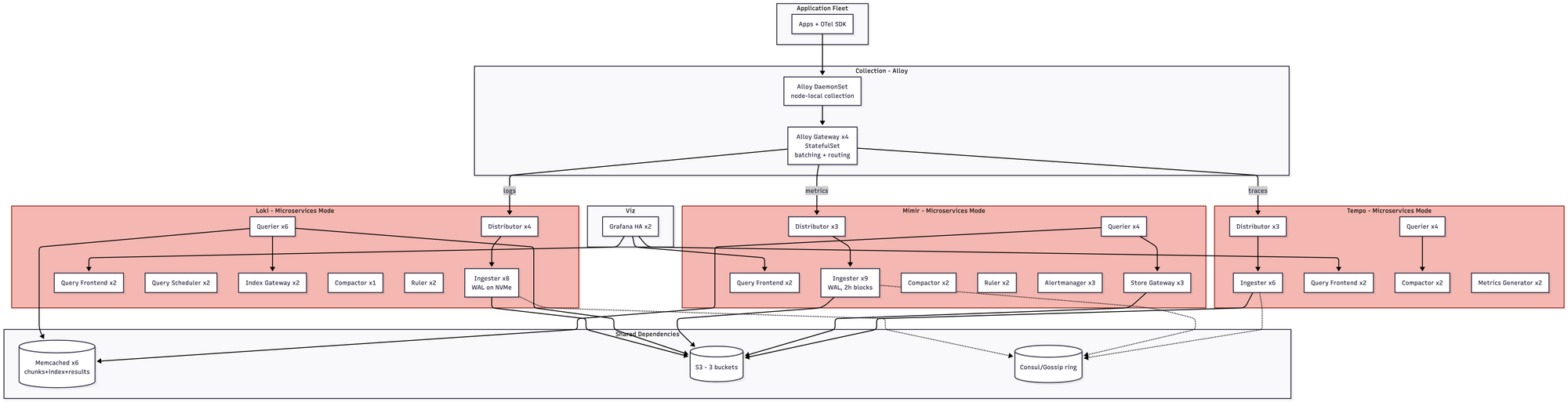
LGTM stack
You are now in microservices mode, whether you wanted to be or not. That means 65+ pods across three separate systems, each with its own compaction pipeline, its own hash ring, its own memcached tier. The gossip/memberlist ring becomes a real operational concern; ingester rollouts require careful -ingester.autoforget-unhealthy tuning, and if you get it wrong you either lose data or duplicate it. Roughly $22–32K/month.
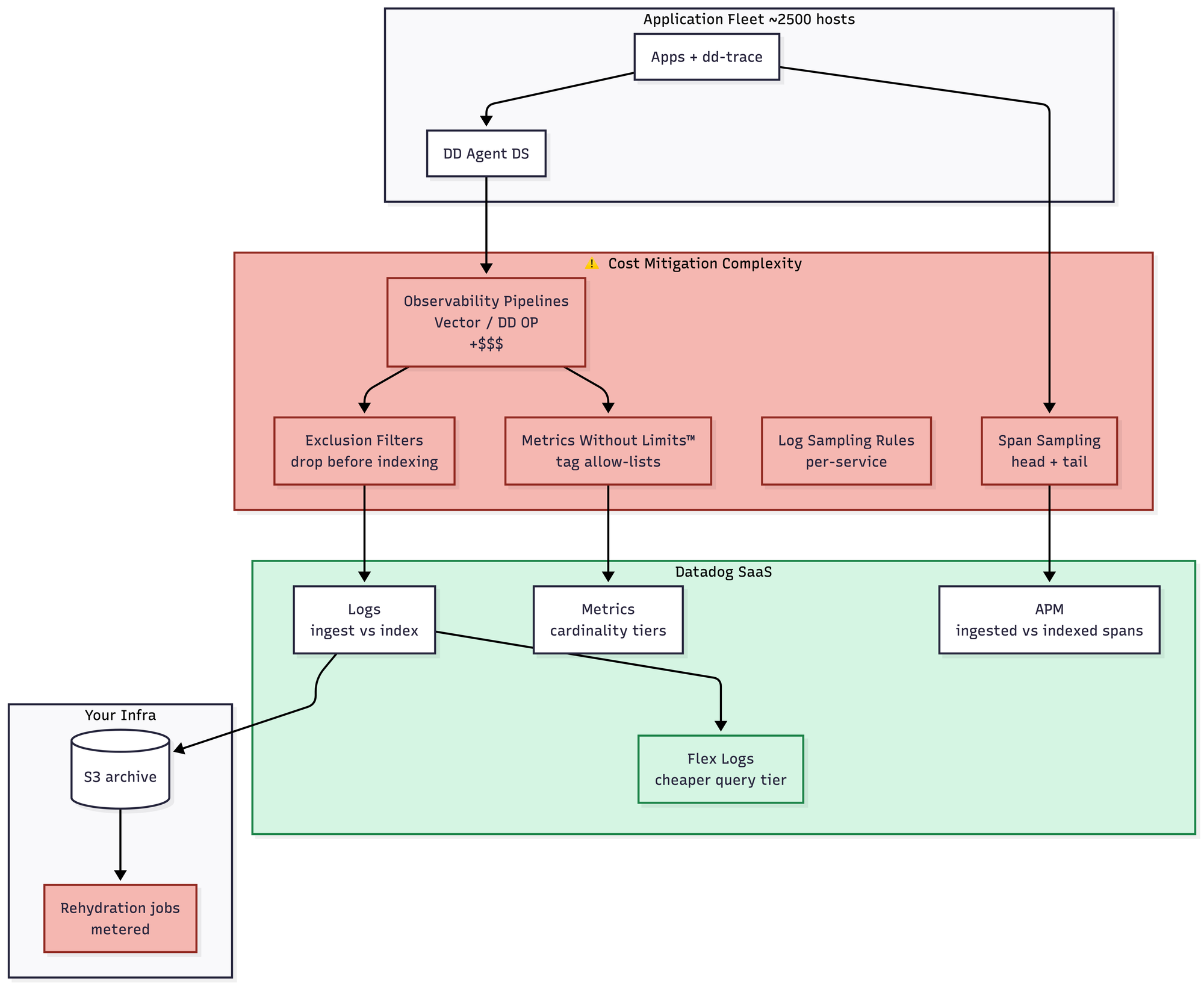
Datadog
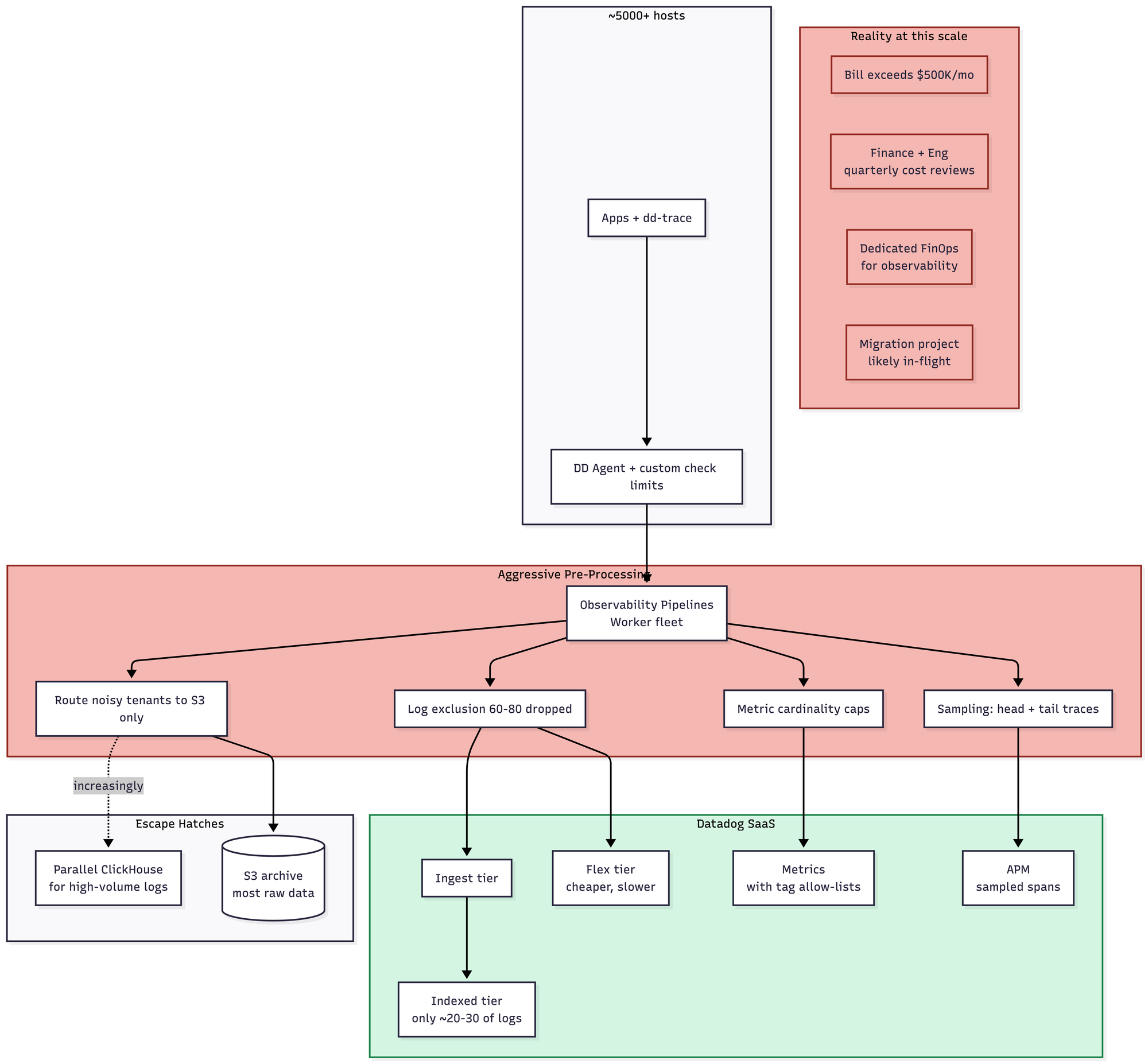
The operational complexity is still low, in that you don't run any servers. But you now need a full pipeline team whose entire job is reducing your Datadog bill. Exclusion filters, sampling rules, cardinality caps, tag allow-lists, the whole apparatus. This is what I call the "you build a system to avoid using the system you're paying for" trap, and once you're in it, you are in it forever. Roughly $180–350K/month, depending on how aggressive the pipeline team gets.
This is also where you are basically fighting with your SaaS provider all the time, pouring over their billing documentation to figure out how to reduce costs. It's a hostile relationship and one I don't enjoy.
Clickhouse
You'll notice, if you look at the diagram, that I basically just added shards. That's it. That's the change. Same operator, same query engine, same query language, same mental model. Rebalancing after adding shards is manual, which is a real trade-off — most teams pre-provision or use weighting on Distributed tables to sidestep it. Materialized views for dashboard rollups shift from "nice to have" to "essential." Roughly $7–11K/month.
The gap between ClickHouse and everything else opens up here. It doesn't close.
10 TB a Day
This is where most solutions genuinely stop working, in the sense that even a well-staffed internal team cannot keep up with the operational load.
Elasticsearch
You are now running three separate Elasticsearch clusters — one for logs, one for metrics, one for APM — federated through Cross-Cluster Search. Hot-tier NVMe cost dominates the bill. This is the scale at which teams start seriously evaluating alternatives, and where a lot of the recent migrations to ClickHouse have originated. Roughly $95–140K/month plus commercial licensing.
You need people who are legitimate experts on Elasticsearch. Now thankfully Elastic just laid a ton of those people off, so they're probably possible to get, but still. Running this thing at this size is very complicated.
LGTM
Around 180+ pods, zone-aware everything, split-and-merge compaction, per-tenant limits, shuffle sharding to prevent noisy neighbors. You almost certainly have a dedicated observability platform team of three to five engineers at this point. If you don't, get ready for a bad fucking time. Roughly $55–85K/month.
Datadog
Still very easy to run, in the strict sense that you don't run anything. But your bill is now measured in six or seven figures a month, and the org has almost certainly built a pre-processing pipeline team whose entire existence is dedicated to reducing that bill. Most companies at this scale have gone hybrid: Datadog for APM and high-value metrics, self-hosted (increasingly ClickHouse) for logs. The complexity paradox at this scale is that you now have Datadog's simplicity plus your pipeline complexity plus a second self-hosted stack. Pricing is all over the goddamn place. You might be over a $1 million a month here.
Clickhouse
Look at the diagram and then look back at the 1 TB diagram. It's the same diagram. There are more shards. That's the difference. Materialized views for rollups are now mandatory rather than optional. Schema design mistakes you made two years ago will start to hurt, so hopefully you didn't make many. Rebalancing after adding shards is still manual; most teams pre-provision or use clickhouse-copier or a dual-write migration when they need to grow the cluster. Kafka starts to become useful as a buffer for very bursty ingest, though it's not required. Roughly $18–28K/month.
What does this mean?
If you've read this far, the point is probably already obvious, but I want to say it directly.
Every observability stack works at 1 TB a day. If you're small, pick whatever your team already knows. Life is short. We're all just waiting for the robots to kick our heads off like soccer balls.
The question is not which stack works today. The question is which stack still resembles itself two years from now, when your data volume has 5x'd and your team has 2x'd and the person who originally designed the whole thing has left the company.
Elasticsearch mutates. LGTM mutates. Datadog stays operationally simple but mutates financially into something that requires its own dedicated team of accountants and pipeline engineers just to keep the bill from spiraling.
ClickHouse just gets wider. You add shards. That's the whole trick.
There is a real cost to this: you have to eat the schema-design and query-engine complexity up front, at a scale where the other options are objectively easier. You will be, briefly, the one making things harder for your developers. They will not always appreciate this. But the trade you're making is that their experience — and yours — remains roughly the same as the data grows by an order of magnitude, and the next order of magnitude, and probably the one after that.
I have spent ten years watching observability stacks change shape underneath me while I tried to keep them running. ClickHouse is the first one that hasn't and that has been able to actually scale with me. That's pretty incredible.
I like the Internet. I am old enough to remember the pre-Internet era and despite the younger generations pining for those simpler days, I was there. Paper maps were absolutely horrible, just you and a compass in your car on the side of the road in the middle of the night trying to figure out where you are and where you are going. Once when driving from Michigan to Florida I got so lost in the middle of the night in Kentucky that I had to pull over to sleep and wait for the sun so I could figure out where I was. I awoke to an old man staring unblinkingly into my car, shirtless, breathing heavy enough to fog the windows. To say I floored that 1991 Honda Civic is an understatement.
You would leave your house and then just disappear. This is presented as kind of romantic now, as if we were just free spirits on the wind and could stop and really watch a sunset. In practice it was mostly an annoying game of attempting to guess where people were. You'd call their job, they had left. You'd call their house, they weren't home yet. Presumably they were in transit but you actually had no idea. As a child my response to people asking me where my parents were was often a shrug as I resumed attempting to eat my weight in shoplifted candy or make homemade napalm with gasoline and styrofoam. Sometimes I shudder as a parent remembering how young I was putting pennies on train tracks and hiding dangerously close so that we could get the cool squished penny afterwards.
Cassettes are the worst way to listen to music ever invented. Tapes squealed. Tapes slowed down for no reason, like they were depressed. Multiple times in my life I would set off on a long road trip, pop in a tape, and within fifteen minutes watch as it shot from the deck unspooled like the guts from the tauntaun in Star Wars. You'd then spend forty-five minutes at a Sunoco trying to wind it back in with a Bic pen knowing in your heart you were performing CPR on a corpse. Then you'd put it back in the player out of pure stubbornness, and it would chew itself again immediately, and you'd drive the next six hours in silence with your own thoughts, which were not as good as Pearl Jam.
So I am, mostly, grateful for the bounty the internet has provided. But there is something wrong, deeply wrong, with what we built. The wrongness was there at the start. It was baked into the foundation by people who told themselves a story about freedom, and that story was a lie, and we are all, every one of us, paying their tab.
To understand what happened we need to go back to the 90s.
A Declaration of the Independence of Cyberspace
One of the first and most classic examples of the ideology that powered and continues to power tech is the classic "A Declaration of the Independence of Cyberspace" by John Perry Barlow written in 1996. You can find the full text here. I remember thinking it was genius when I first read it. I was young enough that I also thought "Snow Crash" was a serious political document. Today the Declaration reads like one of those sovereign citizen TikToks where someone in traffic court is claiming diplomatic immunity under maritime law.
It helps to know who Barlow was. Barlow was a Grateful Dead lyricist. He was also a Wyoming cattle rancher. He was also, briefly, the campaign manager for Dick Cheney's first run for Congress. (You did not misread that.) He spent his later years as a fixture at Davos, the World Economic Forum, where the very wealthy gather each January to remind each other that they are interesting. It was at Davos, in February 1996, fueled by champagne and grievance over the Telecommunications Act, that Barlow banged out the Declaration on a laptop and emailed it to a few hundred friends. From there it became, somehow, one of the founding documents of the modern internet.
These increasingly hostile and colonial measures place us in the same position as those previous lovers of freedom and self-determination who had to reject the authorities of distant, uninformed powers. We must declare our virtual selves immune to your sovereignty, even as we continue to consent to your rule over our bodies. We will spread ourselves across the Planet so that no one can arrest our thoughts.
Many of the pillars of "modern Internet" are here. Identity isn't a fixed concept based on government ID but is a more fluid concept. We don't need centralized control or really any form of control because those things are unnecessary. It was this and the famous earlier "Cyberspace and the American Dream: A Magna Carta for the Knowledge Age" that laid a familiar foundation for a lot of the culture we now have. [link]
The Magna Carta is also our introduction to the (now familiar) creed of "catch up or get left behind". The adoption of new technology must be done at the absolute fastest speed possible with no regulations or checks. You don't need to worry about the consequences of technology because these problems correct themselves. If you told me the following was written two weeks ago by OpenAI I would have believed you.
If this analysis is correct, copyright and patent protection of knowledge (or at least many forms of it) may no longer be unnecessary. In fact, the marketplace may already be creating vehicles to compensate creators of customized knowledge outside the cumbersome copyright/patent process
The cumbersome copyright/patent process. Cumbersome to whom, exactly? This is always the move. The thing your industry would prefer not to deal with is reframed as an obsolete burden. Your refusal to do it is rebranded as innovation. Your inability to imagine a world where you don't get exactly what you want becomes a manifesto.
Winner Saw It Coming
So there are dozens of these pieces and they all read the same. If you don't regulate these technologies humanity will only benefit. Education, healthcare, industry, etc. We don't need regulations because the transformation from the medium of paper to digital has transformed the human spirit. But one was extremely surprising to me. Langdon Winner wrote something almost prophetic back in 1997. You can read it here.
He coins the term cyberlibertarianism (or at least is the first mention of it I could find) and then goes on to describe an almost eerily accurate set of events.
In this perspective, the dynamism of digital technology is our true destiny. There is no time to pause, reflect or ask for more influence in shaping these developments. Enormous feats of quick adaptation are required of all of us just to respond to the requirements the new technology casts upon us each day. In the writings of cyberlibertarians those able to rise to the challenge are the champions of the coming millennium. The rest are fated to languish in the dust.
Characteristic of this way of thinking is a tendency to conflate the activities of freedom seeking individuals with the operations of enormous, profit seeking business firms. In the Magna Carta for the Knowledge Age, concepts of rights, freedoms, access, and ownership justified as appropriate to individuals are marshaled to support the machinations of enormous transnational firms. We must recognize, the manifesto argues, that "Government does not own cyberspace, the people do." One might read this as a suggestion that cyberspace is a commons in which people have shared rights and responsibilities. But that is definitely not where the writers carry their reasoning.
What "ownership by the people" means, the Magna Carta insists, is simply "private ownership." And it eventually becomes clear that the private entities they have in mind are actually large, transnational business firms, especially those in communications. Thus, after praising the market competition as the pathway to a better society, the authors announce that some forms of compe- tition are distinctly unwelcome. In fact, the writers fear that the government will regulate in a way that requires cable companies and phone companies to compete. Needed instead, they argue, is the reduction of barriers to collaboration of already large firms, a step that will encourage the creation of a huge, commercial, interactive multimedia network as the formerly separate kinds of communication merge.
In all he lays out 4 pillars of this ideology.
Technological determinism. The new technology is going to transform everything, it cannot be stopped, and your only job is to keep up. Stewart Brand's actual quote, which Winner pulls out and lets sit there like a body on display, is "Technology is rapidly accelerating and you have to keep up." There's no room to ask whether we want any of this. The wave is coming. Surf or drown.
It does not occur to anyone in this discourse that 'drown' is a choice the wave is making, not a natural law. Waves do not have intentions. Destroying your livelihood and leaving you to rot isn't a requirement of the natural order as much as that would convenient.
Radical individualism. The point of all this technology is personal liberation. Anything that gets in the way of the individual maximizing themselves be it government, regulation, social obligation, your annoying neighbors, is an obstacle to be removed. Winner notes, with what I imagine was a very dry expression, that the writers of the "Magna Carta for the Knowledge Age" cited Ayn Rand approvingly. In 1994. As intellectual grounding. For a document about computers.
There is something deeply funny about a movement claiming to invent the future and grounding its case in a Russian émigré's airport novels about steel barons in love with their own reflections.
Free-market absolutism. Specifically the Milton Friedman, Chicago School, supply-side flavor. The market will sort it out. Regulation is theft. Wealth is virtue. George Gilder, who co-wrote the Magna Carta, had previously written a book called Wealth and Poverty that helped sell Reaganomics to the masses. He then wrote Microcosm, which argued that microprocessors plus deregulated capitalism would liberate humanity. He was very serious about this.
Don't worry, Gilder is still out there. He loves the blockchain and crypto now. He now writes about how Bitcoin will save the soul of capitalism, which it is somehow doing while also destroying the planet. Both can be true in his cosmology. The ideology is flexible like that.
A fantasy of communitarian outcomes. This is the part that should make you laugh out loud. After establishing that government is bad, regulation is theft, and the individual is sovereign, the cyberlibertarians then promise that the result of all this will be... rich, decentralized, harmonious community life. Negroponte: "It can flatten organizations, globalize society, decentralize control, and help harmonize people." Democracy will flourish. The gap between rich and poor will close. The lion will lie down with the lamb, and the lamb will have a Pentium II.
We also have the advantage of hindsight and know, without question, that all of these predicted outcomes were wrong. Not 'directionally wrong' or 'wrong in the details.' Wrong the way it would be wrong to predict that if you set your kitchen on fire, the result will be a renovation.
You have to hold these four ideas in your head at the same time to see the trick. The cyberlibertarians wanted you to believe that radical individualism plus deregulated capitalism plus inevitable technology would produce communitarian utopia. This is, on its face, insane. It is the economic equivalent of claiming that if everyone punches each other really hard, eventually we'll all be hugging.
But Winner's sharpest observation, the one I keep coming back to, isn't about any of the four pillars individually. It's about the move underneath them. He writes:
"Characteristic of this way of thinking is a tendency to conflate the activities of freedom seeking individuals with the operations of enormous, profit seeking business firms."
This is the entire game. This is how "don't tread on me" becomes "Meta should be allowed to do whatever it wants." This is how the rights of the lone hacker working in their garage become indistinguishable from the rights of a multinational with a market cap larger than most countries' GDP. The Magna Carta literally argues that the government should reduce barriers to collaboration between cable companies and phone companies in the name of individual freedom and social equality. Winner caught this in 1997.
That is why obstructing such collaboration – in the cause of forcing a competition between the cable and phone industries – is socially elitist. To the extent it prevents collaboration between the cable industry and the phone companies, present federal policy actually thwarts the Administration's own goals of access and empowerment.
What makes the essay uncomfortable to read now is that Winner wasn't even predicting the future. He was just describing what was already happening and noting where it would obviously lead. He saw the media mergers and asked the question nobody in the industry wanted to answer: what happened to the predicted collapse of large centralized structures in the age of electronic media? Where, exactly, did the decentralization go? He saw that the cyberlibertarians were going to deliver the opposite of everything they promised, and that they were going to keep getting paid to promise it anyway.
He was writing before Google. Before Facebook. Before the iPhone. Before YouTube. Before Twitter, Bitcoin, Uber, AirBnB, OpenAI, and the entire app economy. Before any of the actual examples that would eventually prove him right existed. He just looked at the people doing the talking, listened to what they were saying, and wrote down where it ended. It is not a long essay. He didn't need a long essay. The future was right there on the page, in their own words. He just had to read it back to them.
The essay closes with a question that has, to my knowledge, never been seriously answered by the industry it was aimed at:
"Are the practices, relationships and institutions affected by people's involvement with networked computing ones we wish to foster? Or are they ones we must try to modify or even oppose?"
Twenty-eight years later, the industry still treats this question as somewhere between naive and seditious. It's the question Barlow's declaration was specifically designed to make unaskable. And it remains, to this day, the only question that actually matters.
Caveat emptor
When you look at these early formative writings, so much of what we see now becomes clear. The cyberlibertarian deal was always the same: you're on your own. The industry would build the infrastructure, take the profits, and shove every consequence, every harm, every cost, every responsibility, onto somebody else.
There is no greater example to me than the moderator. Anyone who has ever moderated a forum or a subreddit knows that adding the word "cyber" to a space doesn't suddenly turn people into better humans. People are still people. They flame each other, they post slurs, they doxx, they harass, they spam, they post CSAM, they radicalize each other, they grief, they coordinate, they lie. A space with humans in it requires governance.
They produce, with frightening regularity, the exact behavior any kindergarten teacher could have predicted. Then they act surprised.
But the cyberlibertarian model required pretending it was unforeseeable. The platforms couldn't acknowledge that they needed governance because acknowledging it would mean acknowledging responsibility, and acknowledging responsibility would mean acknowledging liability, and acknowledging liability would mean the entire economic model collapses. So instead the industry invented a beautiful fiction: governance happens, but it happens by magic, performed by volunteers, for free, who we will simultaneously rely on and mock.
Reddit is run by unpaid moderators. Wikipedia is run by unpaid editors. Stack Overflow was run by unpaid experts and is now a ghost town. On TikTok and Twitter it is the unknowable "algorithm" that is the cause of and solution to every problem backed by capricious moderators who delight in stopping free speech. Unless you don't like it, then it's negligence moderation in defense of your enemies.
Open source is run by unpaid maintainers having nervous breakdowns. The platforms collect the rent. The people doing the actual work of making the platforms livable get nothing, and when they ask for anything like recognition, tools, basic protection from harassment, they're told they're power-tripping nerds who should touch grass.
This is also the crypto story, just with the masks off. What if we made worse money on purpose, money that bypassed every protection consumers had won over the previous century, money that couldn't be reversed when stolen, money that funded ransomware attacks on hospitals and pump-and-dumps targeting people's retirement accounts? The cyberlibertarian answer was: that's freedom. The losses were real. People killed themselves. Hospitals had to turn away patients. The architects became billionaires and bought yachts and now sit on the boards of AI companies, where they are reinventing the same con with a new vocabulary.
Now Winner got one thing wrong, and it's worth pausing on, because it's the most interesting wrinkle in all of this. What actually happened was weirder and worse. The cyberlibertarians became the corporations. They didn't sell out. They didn't betray their principles for the first offer of money. They simply scaled until their principles became inconvenient, and then they stopped mentioning them.
Once the platforms got large enough to be unstoppable, once they captured enough of the regulatory apparatus to write their own rules, the libertarian rhetoric got quietly shelved like a college poster you took down before your in-laws came over. Meta no longer pretends it stands for free speech and seemingly takes delight in putting its thumb on the scale. TikTok users have invented an entire euphemistic shadow language to evade automated censorship like "unalive," "le dollar bean," "graped" that would have made 1996 Barlow weep into his bolo tie.
Copyright and patents matter when they're Apple's copyright and patents. Or Googles. Or OpenAIs. Go try to make a Facebook+ website and see how quickly Meta is capable of responding to content it finds objectionable.
Cyberlibertarianism was the ladder. Once they were on the roof, they kicked it away and started charging admission to look at the view.
So the Internet is Doomed?
Remember I like the Internet. I said it in the beginning and it is still true. I love the Fediverse, I love weird Discords about small tabletop RPGs I'm in. I spend hours in the Mister FPGA forums. There are corners that are good. But they're mostly good because they're not big enough to be worth breaking up.
It feels increasingly like I'm hanging out in the old neighborhood dive bar after most of the regulars have moved away. The lighting is the same. The bartender remembers your order. But you can hear yourself think now, and that's mostly because the room is half empty and the jukebox finally died. The new clientele is from out of town. They are taking pictures of the menu.
If we want to have a serious conversation about why we are in the situation we're in, it is no longer possible to pretend that the broken ideology that put us on this trajectory is still somehow compatible with the harsh realities that surround us. It is not clear to me if democracy can survive a deregulated Internet. A deregulated Internet filled with LLMs that can perfectly impersonate human beings powered by unregulated corporations with zero ethical guidelines seems like a somewhat obvious problem. Like an episode of Star Trek where you the viewer are like "well clearly the Zorkians can't keep the Killbots as pets." It doesn't take some giant intellect to see the pretty fucking obvious problem.
If we want to save the parts of the internet worth saving, we have to evolve. We have to find some sort of ethical code that says: just because I can do something and it makes money, that is not sufficient justification to unleash it on the world. Or, more simply: just because I want to do something and you cannot actively stop me, that does not make doing it a good idea. We have waited thirty years for the cyberlibertarian future to arrive and produce the promised harmonious community. It's time to face the facts. It's never coming. The bus left in 1996. The bus was never real.
People did not get better because they went online. Giving everyone access to a raw, unfiltered pipeline of every fact and lie ever produced did not turn them into better-educated people. It broke them. It allowed them to choose the reality they now inhabit, like ordering off a menu. If I want to believe the world is flat, TikTok will gladly serve me that content all day. Meta will recommend supportive groups. There will be hashtags. There will be Discords. There will be a guy named Trent who runs a podcast. I will never have to face the deeply uncomfortable possibility that I might be wrong about anything, ever, until the day I die, surrounded by people who agree with me about everything, including which of the other mourners are secretly lizards.
That is the internet we built. It was not an accident. It was the product of a specific ideology, written down by specific people, at a specific cocktail party in Davos, in 1996. Winner watched it happen and told us where it was going. We did not listen. There is still time, maybe, to start.
My friend and I have a game where we talk about what we'd do if we were rich. Not rich like 'paid off the mortgage' rich. Rich like a man who owns a submarine he's never been inside. Rich like a man whose third wife has a skincare line. Tech-titan rich — the kind of money that buys you a compound in Wyoming and the confidence to wear the same gray t-shirt to congressional testimony."
One of mine, for a long time, has been the dream of making a new forge. I was prompted to write this after reading the good post about Ghostty leaving GitHub but it's something I've written and talked about for a few years. Given how bad GitHub has become at its core job, it seemed like a fun opportunity to try and write up what my billionaire folly of a forge would look like. This folly would have less penile rockets filled with aging celebrities.
What are the problems with modern forges?
GitHub, GitLab and Gitea (those being the 3 I've used the most) are all modeled on effectively the same design. There are differences, but you can tell that GitHub sets the pattern for the industry and then those features are ported over to the other two with varying levels of success. Almost nothing in the forge has any relationship to git so the client has become completely disconnected from the practical usage.
Git is great at what it is designed to do, but what it is designed to do isn't the way most people are using it. Git is a perfect tool for kernel development. It is a decentralized distributed version control system that relies on the idea of patches being sent to maintainers over email. You trust those maintainers to maintain their sections and merge in the stuff that makes sense and not merge in the other stuff. It's a pretty high trust environment that places very few restrictions on how online a specific contributor is or what system they are using. If you have a laptop from 2010 that connects to the Internet once a week you can still be a meaningful contributor to a project with these workflows. .
However, in most jobs, git is effectively just the way I pull and push from a centralized repository stored in a forge. All the important stuff happens inside the forge, and very little of it happens on my client. Pull Requests are how I enforce the four-eyes principle, GitHub Actions are how I run my tests and linting on those Pull Requests to ensure they are functional and meet my organizational requirements, the user's identity in relation to that forge is how I verify who they are. I track issues with my code through Issues and cut releases for users to download through Releases. There's not a lot of git in this workflow, this is mostly placed on top of git.
So if we sort of don't care about what the client is really doing then there's no reason to be bound to git, since we're effectively free from that constraint. If we're gonna make a new forge I'd want it to do the following, ideally designed to work with the client to expose this stuff better.
Stuff happens in the wrong order. You know the PR. Commit 1: 'Feature.' Commit 2: 'fix.' Commit 3: 'fix.' Commit 4: 'actually fix.' Commit 5: 'please.' Commit 6, made at 11:47 PM on a Thursday: 'asdfasdf'. This person has a family. This person has hobbies. This person is, at this moment, crying. You don't want the feedback loop after the commit you want it before. Let me do an enforced pre-commit hook to run the jobs remotely on the forge and provide the feedback to the user before they push.
PR approval is too boolean. The PR is approved or it's not approved. Real code review, like real life, lives in the middle. 'Sure, fine, we'll deal with it later' is a legitimate human response and should be a legitimate button. Gerrit has a better model for this. If I weakly approve something as a maintainer, let me flag it for later.
PRs are too inflexible. I don't need 4 eyes on every change, especially in a universe where LLMs exist. The global GDP lost annually to senior engineers staring at a four-line PR waiting for someone — anyone — to type 'LGTM' could fund a moon mission. A nice one. With legroom. Let me customize and more easily control this. If the person is a maintainer and the LLM says its low risk/no risk just let them go.
Stacked PRs are just better. They're easier to review and understand. They have to be a first-class citizen not an add-on through a tool other than your VCS.
A forge shouldn't do everything. Issue tracking yes. Kanban board, probably not. Wiki? I doubt it. Everything tools always turn into crap. You add features when its easy to add features and then pay the maintenance price for those features forever regardless of their rate of adoption because now someone, somewhere uses them and you are locked in.
The standard unit of hosting is too large. Running Github Enterprise is a big task. Running GitLab is also a relatively big ask. These are complicated products with a lot of moving pieces. I want smaller individual units of hosting that I can link together to make an organization. It's fine if they're not globally federated and I need to make an account for each Organization, but an Organization should be flexible enough to let me say "these 12 Raspberry Pis are my org". I don't know how they communicate securely, I hire people for that problem.
My local copy of the repo should be a representation of the entire repo, not just the code. I should be able to approve a PR from the same VCS I use to check in the code. I should be able to go through my issues by looking through local files.
On the flip side, since I need to be online all the time to really work with a team, don't make me pay the storage price all the time. I want my VCS and my forge to work together. If I clone a repo, I want a pretty limited history for that repo when I clone. If I start to go back in time, spin up a worker to go fetch that stuff from the VCS when I need it. I don't need to hammer the forge with giant clone requests on the assumption that I might need to rebuild the forge at any moment with the entire history of the entire project.
Actions need to be signed, SHA'd and usable offline. If I want, I should be able to get tarballs of all my actions, stick them in the repo and tell my system "don't go anywhere for checkout action, that's right here". If I say latest, have that work like Dependabot does now where it opens up a PR to put the latest tarballs in my repo. Actions are critical and they should be runnable on my local machine through the same VCS if I want to.
Well Y Does Some Of That
Absolutely. There are a lot of tools that do parts of this. I want someone to take them, put them all together and fit them up. I want JJ as the VCS, I want this as the forge and I want the expectation that I as a user could live happily with a raspberry pi as a forge for a long time. I want those forges designed around modern concepts like object storage and shallow clones and getting constantly hammered by LLM bots.
Now in a universe where GitHub was doing a good job, I wouldn't even bother writing this up. GitHub is the default and talking to people about overcoming the default is usually a waste of time. Heinz is the default ketchup, when I order a Coke I don't want a Pepsi and if I'm going to use a forge up until 2026 there would have to be an amazing reason for me to not choose the one that everyone uses. Up until recently other forges have been like sweet potato french fries, which is to say never the thing you actually want.
But we live in a world where the monolithic forge is breaking down and nobody has built the replacement. The people with the money are busy with the rockets. The people with the taste are busy with their day jobs. And the rest of us are opening PRs titled 'asdfasdf' at midnight, waiting for a robot to check them, wondering when the tool we spend our whole working lives inside stopped being built for us.
If I ever get the submarine money, I'll let you know.
I write stuff here. Sometimes the stuff is good. Sometimes it reads like I wrote it at 2 AM after an argument with a YAML file, which is because I did. But one decision I made early on was that I didn't want to offer an email newsletter.
Part of this was simple economics. At one point I did have a Subscribe button up, and enough people clicked it that the cost of actually sending those emails started to resemble a real bill. Sending thousands of emails when you have no ads, no sponsors, and no monetization strategy beyond "I guess people will just... read it?" doesn't make a lot of financial sense.
But the bigger reason — the one I actually care about — is that I didn't want a database full of email addresses sitting under my control if I could possibly avoid it. There's a particular flavor of anxiety that comes with being the custodian of other people's personal data, a low-grade dread not unlike realizing you've been entrusted with someone's elderly cat for two weeks and the cat has a medical condition. I can't lose data I don't have. I never need to lie awake wondering whether some user is reusing their bank password to log into my website just to manage their subscription preferences. The best way I can safeguard user data is by never having any in the first place. It's not a security strategy you'll find in any textbook, but it is airtight.
Now, when I explained this philosophy to people who run similar websites, the reaction was — and I'm being generous here — warm laughter. The kind of laughter you get when you ask if an apartment in Copenhagen is under $1,000,000. Email newsletters are the only way to run a site like this, they said. RSS is dead, they said. You might as well be distributing your writing via carrier pigeon or community bulletin board. One person looked at me the way you'd look at someone who just announced they were going to navigate cross-country using only a paper atlas. Not angry. Just sad.
I'm lucky in that I'm not trying to get anyone to pay me to come here. If I were, the math would probably change. I'd be out there A/B testing subject lines and agonizing over open rates like everyone else, slowly losing pieces of my soul in a spreadsheet. But if your question is simply, "Can I make a hobbyist website that actual humans will find and read without an email newsletter?" — the answer is a resounding yes. And I have the logs to prove it.
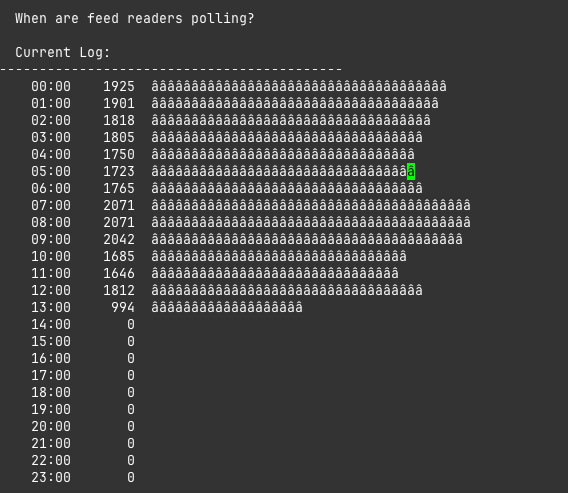
These logs get rotated daily and don't include the majority of requests that hit the Cloudflare cache before they ever reach my server, so the real numbers are higher. But I think they're reasonably representative of the overall shape of things. About half my traffic is readers hitting /feed or /rss — people who have, of their own free will, pointed an RSS reader at my site and said yes, tell me when this person has opinions again. The other half are arriving via a specific link they stumbled across somewhere in the wild.
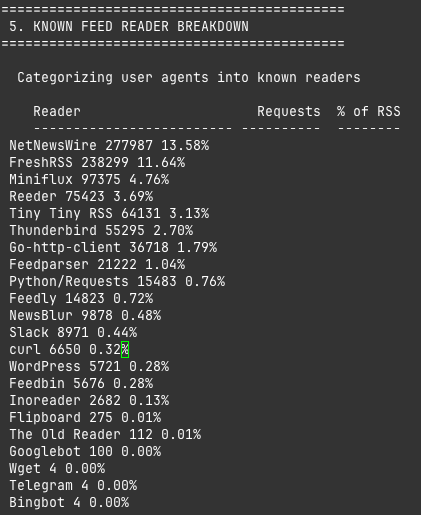
If we do a deeper dive into that specific RSS traffic, we learn a few interesting things.
The user-agent breakdown shows the usual suspects — the RSS readers you'd expect, the ones that have been around long enough to have their own Wikipedia articles. There are also some abusers in the metrics. I have no idea what "Daily-AI-Morning" is, but whatever it's doing, it's polling my feed with the frantic energy of someone refreshing a package tracking page on delivery day.
The time distribution, though, is pretty good — spread out across the day in a way that suggests real humans checking their feeds at real human intervals, rather than a single bot hammering me every thirty seconds.
My conclusion is this: if you want to run a website that relies primarily on RSS instead of email newsletters, you absolutely can. The list of RSS readers hasn't dramatically changed in a long time, which is actually reassuring — it means the ecosystem is stable, not dead. The people who use RSS really use RSS. They're not trend-chasers. They're the type who still have a working bookmark toolbar. They are, in the best possible sense, your people.
Effectively, if you make your site RSS-friendly and you test it in NetNewsWire, you will — slowly, quietly, without a single "SUBSCRIBE FOR MORE" pop-up — build a real audience of people who actually want to read what you write. No email database required. No passwords to leak. No giant confusing subscription system.
Companies, as they grow to become multi-billion-dollar entities, somehow lose their vision. They insert lots of layers of middle management between the people running the company and the people doing the work. They no longer have an inherent feel or a passion about the products. The creative people, who are the ones who care passionately, have to persuade five layers of management to do what they know is the right thing to do. - Steve Jobs
I don't typically write about Apple stuff. It's the most written-about company on earth. Every product launch gets the kind of forensic scrutiny normally reserved for plane crashes and celebrity divorces.
Mostly though, I feel like a line cook at a Denny's talking trash about whether the French Laundry has lost their way. I'm back here microwaving a Grand Slam and opining about Thomas Keller's sauce work. The engineers I know personally at Apple are, on average, much more talented than me. They work harder, they do it for decades without a break, and none of them have ever shipped a feature while still wearing pajama pants at 2 PM. It seems insane for someone of my mediocre talent to critique them.
It also feels a little dog-pile-y. Apple employees know Tahoe sucks. They know it the way you know your haircut is bad — they don't need strangers on the internet confirming it. And to be fair, there's genuinely great work buried inside Tahoe: the clipboard manager, the automation APIs, a much-improved Spotlight. But visually it's gross, and that matters when your entire brand identity is "we're the ones who care about design."
Instead, I want to talk about a bigger problem and one that I do feel qualified to talk about because I am very guilty of committing this sin. I don't see a cohesive vision for MacOS and WatchOS. This, more than one bad release, seems far worse to me and dangerous for the company. Since this is already 2000 words as a draft I'll save WatchOS for another time. I'm verbose but even I have limits.
Now to be clear this isn't across every product. iPadOS has a strong vision and have the strength of their convictions to change approaches. The different stabs at solving the window problem inside of the iPad and make it so that you still have an iPad experience while being able to do multiple things at the same time is proof of that. iOS has an incredibly strong vision for what the product is and isn't and how the software works with that.
VisionOS and tvOS are less strong, but visionOS is still finding its footing in a brand new world. The Apple TV hardware and software is in a weirdly good position even though nothing has changed about it in what feels like geological time. I've purchased every version of the Apple TV, and with the exception of that black glass remote — the one that felt like it was designed by someone who had never held a remote, or possibly a physical object — everything has been pretty good. I'm still not clear how storage works on the Apple TV and I don't think anybody outside of Apple does either. I'm not even sure Apple knows. But somehow it's fine.
But with watchOS and MacOS we have 2 software stacks that seem to be letting down the great hardware they are installed in. They seem to be evolving in random directions with no clear end goal in mind. I used to be able to see what OS X was aiming for, even if it didn't hit that goal. Now with two of Apple's platform I'm not able to see anything except a desire to come up with something to show as this years release.
OS X Has An Opinion
When I got my first Mac — an iBook G3 — the experience was like test-driving a Ferrari that someone had fitted with a lawnmower engine. You'd click on the hard drive icon and wait. And wait. And in those few seconds of waiting, you'd think: man, this would be incredible if the hardware could keep up. The software had somewhere it wanted to go. The hardware just couldn't get it there yet.
This trend continued for a long time on OS X, where you'd see Apple really pushing the absolute limits of what it could get away with. After the rock solid stability of 10.4 Apple took a lot of swings with 10.5 and they didn't all land. The first time you opened the Time Machine UI and the entire thing crawled to an almost crash, you'd think boy maybe this wasn't quite ready for prime time. But this entire time there wasn't really a question, ever, that there was a vision for what this looked like.
10.5 Time Machine
The progression of OS X from the beta onward was this:
It's Unix, but you never need to know that. All the power, none of the beard. You get the stability of a server OS without ever having to type sudo into anything.
Everything annoying is abstracted away. Drivers? Gone. "Installing" an application? You drag it into a folder. That's it. That's the install. It felt like the computer was meeting you more than halfway — it was practically doing your job for you and then apologizing for not doing it sooner.
If it seems like it should work, it works. Double-click a PDF, it opens. Put in a DVD, it plays. Drag an app to the Applications folder and it becomes an application. This sounds obvious now, but in 2003 this was like witchcraft if you were coming from Windows.
But it was also serious. It wasn't cluttered with stupid bullshit. It was designed for people who made things — with real font management, color calibration, the works. The OS tried to stay out of your way. Your content was the show; everything else was stagecraft.
OS X tried to accommodate you, not the other way around. When you look at these screenshots I'm always surprised how light the touch is. There isn't a lot of OS here to the user. Almost everything is happening behind the scenes and the stuff you do see is pretty obvious.
The first time I thought "oh man, they've lost the thread" was Notifications. On iOS, Notifications make sense — you've got apps buried in folders three screens deep, so a unified system for surfacing what's happening is genuinely useful. On macOS, this design makes absolutely no sense at all. You can see your applications. They're right there. In the Dock. Which is also right there.
This is the beginning of this feeling of "we aren't sure what we're doing here with the Mac anymore". iOS users like Notifications so maybe you dorks will too? It consumes a huge amount of screen real estate, it was never (and still isn't) clear what should and shouldn't be a notification. Even opening up mine right now it's filled with garbage that doesn't make sense to notify me about. A thing has completed running the thing that I asked it to run? Why would I need to know that?
There is also already a clear way to communicate this information to me. The application icon adds an exclamation point or bounces up and down in the dock. With Notifications you end up with just garbage noise taking up your screen for no reason. Maybe worse, it's not even garbage designed with the Mac in mind. It's just like random crap nobody cares about that looks exactly like iOS Notifications.
The issue with copying everything from iOS is that it's like copying someone's homework — except they go to a different school, in a different country, studying a different subject. It's not just wrong in the way where you tried and failed. It's wrong in a way that makes everyone who encounters it deeply uncomfortable. The teacher doesn't even know where to begin. They just stare at it.
For years afterwards it seemed like the purpose of MacOS was just to port iOS features to the Mac years after their launch on iOS. Often these didn't make much sense or hadn't had a lot of effort expended in making them very Mac-y. Like there was clearly a favorite child with iOS, then a sassy middle child with iPadOS and then, like a 1980s sitcom where there was a contract dispute, "another child" you saw every 5th episode run down the stairs in the background with no lines. Me at home would shout at my TV "I knew they didn't kill you off MacOS!".
Pour one out for Apple's most hated product. RIP bud.
Now with Tahoe there's clearly some sort of struggle happening inside of the team. And here's what's maddening — buried inside this visual catastrophe, someone at Apple is doing incredible work. Clipboard management has been table stakes in the third-party ecosystem for years. Apple finally added a version that handles 90% of use cases. It's classic Sherlocking: Apple shows up ten years late to the party, brings a decent bottle of wine, and somehow half the guests leave with them.
Same with Spotlight. Spotlight hasn't gotten a ton of love in years. Suddenly it's really competing with third-party tools. If you're searching for a file, you can filter it based on where the file is stored. Type "name of Directory" press the Tab key, and then type the name of the file before pressing Enter. This is great! We finally have keyword search for stuff like kind:reminder. Application shortcuts for opening stuff with things like ff for Firefox is nice. Assign a quick key like “se” to Send Email. Type it in Spotlight, hit enter, and compose your message.
This is all classic Apple thinking which is "how can we make the Mac as good as possible such that you, the user, don't need to download any third-party applications to get a nice experience". You don't need a word processor, you have a word processor and a spreadsheet application and presentation software and a PDF viewer and a clipboard manager and a system launcher and automation APIs etc etc etc. This is a vision that is consistent throughout the entire systems history, how can we help you do the things you need to do more easily.
But the reason why I'm stressed as someone who is pretty invested in the ecosystem is that the visual stuff is so bad and not just bad, but negligent. We didn't test how it was gonna look under a bunch of situations so that's now someone else's problem. Whenever I get a finder sidebar covering folder contents so I had to resize the window every time, or the Dock freaks out and refuses to come back out, it feels like I installed one of those OS X skins for a Linux distro. I buy Apple stuff cause its nice to look at and this is horrible to look at.
Why is this so big? Why did you cut off the word "Finder" from Force Quit? Everywhere you look there's a million of these papercuts. We have a resolution on our laptops screen that would have made people collapse in 2005 why must we waste all of it on UI elements? Also you can't grab window edges as shown by the best post ever written here: https://noheger.at/blog/2026/01/11/the-struggle-of-resizing-windows-on-macos-tahoe/
Why is there so much empty space between everything? Why are there six ways to do literally everything? Why did we copy the concept of Control Center from iOS at all if there's very little limit on screen real estate and we could already do this from the menu bar? So we're going to keep the Mac menu bar but we're going to add a full iPad control system and then we're going to use the iPad control system to manage the menu bar.
I will say the "Start Screen Saver" makes me laugh because its a mistake I would make in CSS. The text is too long so the button is giant but we didn't resize the icon so it looks crazy. Now do we need the same text inside the button as outside of it? No, and that leads me to the other banger. It's pretty clear the two white boxes inside of "Scene or Accessory" were supposed to be text, Scene on the top and then Accessory on the bottom, but SwiftUI couldn't do that so they left the placeholder. Somewhere there is a Jira ticket to come back to this that got trashed.
Also, complete aside. Has anyone in the entire fucking world ever run Shazam from a Mac? What scenario are we designing for here? I hear a banger at the coffee shop so I hold my MacBook Pro up over my head like John Cusack in Say Anything, hoping it catches enough audio before my arms give out? "Recognize Music" is in my menu bar, taking up space that could be used for literally anything else, on the off chance I need to identify a song using a device that weighs four pounds and has no microphone worth using in a noisy room. If you are going to copy ipadOS's homework you need to think about it for 30 seconds.
So my hope is that the improvement camp wins. That the people who built the better Spotlight and the clipboard manager and the automation APIs are the ones who get to set the direction. Because right now it feels like the best work on macOS is being done in spite of the overall vision, not because of it. Like someone's sneaking vegetables into a toddler's mac and cheese. The good stuff is in there — you just have to eat around a lot of neon orange nonsense to find it.
Steve Jobs talked about creative people having to persuade five layers of management to do what they know is right. I don't know how many layers there are now. But I know what it looks like when the creative people are losing that argument, and I know what it looks like when they're winning it. Right now, on macOS, it looks like both are happening at the same time, in the same release, on the same screen. And that's scarier than any one bad design choice.
In the nightmarish world of 2026 it can be difficult to know how to help at all. There are too many horrors happening to quickly to know where one can inject even a small amount of assistance. However I wanted to quickly post about something I did that was easy, low impact and hopefully helps a tiny fraction of a fraction of a percent of people.
Snowflake
So I was browsing Mastodon when someone posted a link asking for people to host Snowflake proxies. Snowflake is a lightweight proxy best explained by David Fifield below.
So, in summary, Snowflake is a censorship circumvention system, and what that means is, it's a way of enabling network communication between two endpoints despite the presence of some adversary in the middle, a censor in the middle, who's interfering with the communication. Now, that's kind of an abstract, scientifically useful definition of censorship, but this model is, of course, motivated by real-world considerations, actual censorship people encounter in practice. It's security and privacy, but it's also tied up with human rights and freedom of expression, and that's why we do this work. There are a lot of networks in the world—I won't belabor the point—but there are a lot of networks where, you want to read some news, you want to use some app, you want to participate in some discussion group, and you can't. Or you cannot easily, because there's a censor preventing you from doing so. And to give you an idea of the types of things we see in practice, a censor can do stuff like block IP addresses, it can inject RST packets to tear down TCP connections, it can give you false answers to DNS queries, and these are all very commonly seen in practice.
So there are a lot of different circumvention systems, using a variety of different techniques, what is Snowflake's angle? In a nutshell, Snowflake uses a large network of very lightweight, temporary proxies, which we call snowflakes, and they communicate using WebRTC protocols. So when I say "temporary proxies," what I mean by that is that these proxies are allowed to appear and disappear at any time. So the pool is, kind of, constantly changing, and you don't depend on these proxies to be reliable. And WebRTC is a suite of protocols that are often used for real-time communication on the web. So: audio, video, text chat, online games, a lot of these things use WebRTC.
Now we're we're equipped to answer the following two questions. And if you are accustomed, if you're used to censorship research, these answers to these two questions will tell you most of what you need to know to understand what Snowflake is doing. And you'll also understand why these are the two critical questions to ask. If you're not so familiar with this research field, I hope to give you a little bit of familiarity with why these are important questions through the course of this talk. The first questions is: How does Snowflake resist address-based blocking? Well, the answer there is the pool of temporary proxies. It's large, and by "large" you should think, about 100 thousand, and it's not always the same 100 thousand, which is important. Making proxies very easy to run is part of achieving this large proxy pool. The second question is: How does Snowflake resist content-based blocking? Well, that's WebRTC. Rather than transmit client traffic in the clear, we wrap it in an encrypted WebRTC container.
Now, our team started the Snowflake project in order to innovate in the circumvention space, to explore a different combination of parameters and see how well it works. It turns out, it works quite well. But this is more than a research prototype. This has been in serious deployment for three or more years. We serve actual users on an ongoing basis. We have to care about operations, and things like that. It is a built-in circumvention option in Tor Browser, so in Tor Browser you can just choose "Snowflake" from the menu and you'll be using Snowflake. And at any given time we're serving an average of a few tens of thousands of users.
Effectively it is a lightweight and easy to run way to bypass censorship that doesn't require running a VPN and involves almost zero technical knowledge. It's quite the design and one that I kept shaking my head thinking "man I never would have thought of this in a mission years" as I read more about how it works.
So I have a box sitting on an internet connection where I'm lucky enough to have plenty of excess capacity. I figured "why not share it". I thought I'd post the process here in case people were curious but were worried about how much bandwidth it might use or how many resources.
Running Snowflake
Setting it up on a Debian box took like 5 minutes.
CPU usage is quite low, Memory is slightly higher than I would have thought but that's likely a function of running for so long. Remember you can modify the systemd service file to limit memory if you are interested in running this yourself but are concerned about crossing a gig of memory.
[Service]
MemoryMax=512M
All in all I haven't noticed I'm running this at all. Obviously its great to run the browser extension to increase the pool of IP addresses and keep them from becoming static and blockable, but if you have a dedicated box with a large amount of bandwidth and are looking for a quick 20 minute project to help out people trying to deal with internet censorship, this seems like a good one to me.
I have always enjoyed the act of typing words and seeing them come up on screen. While my favorite word processor of all time might be WordPerfect (here), I've used almost all of them. These programs were what sold me on the entire value proposition of computers. They were like typewriters, which I had used in school, except easier in every single way. You could delete things. You could move paragraphs around. It felt like cheating, and I loved it.
As time has gone up what makes up a "document" in word processing has increased in complexity. This grew as word processors moved on from being proxies for typewriters and into something closer to a publishing suite. In the beginning programs like WordPerfect, WordStar, MultiMate, etc had flat binary files with proprietary formatting codes embedded in there.
When word processors were just proxies for typewriters, this made a lot of sense. But as Microsoft Word took off in popularity and quickly established itself as the dominant word processor, we saw the rise of the .doc file format. This was an exponential increase in complexity from what came before, which made sense because suddenly word processors were becoming "everything tools" — not just typing, but layout, images, revision tracking, embedded objects, and whatever else Microsoft could cram in there.
The .doc: A Filesystem Inside Your File
At its base the .doc is a Compound File Binary Format, which is effectively just a FAT file system with the file broken into sectors that are chained together with a File Allocation Table.
It's an interesting design. A normal file system would end up with sort of a mess of files to try and contain everything that the .doc has, but if you store all of that inside of a simplified file system contained within one file then you could optimize for performance and reduced the overhead that comes with storing separate objects in a flat file. It also optimizes writes, because you don't need to rewrite the entire file when you add an object and it keeps it simple to keep revision history. But from a user perspective, they're "just" dealing with a single file. (Reference)
The .doc exploded and quickly became the default file format for humanity's written output. School papers, office memos, résumés, the Great American Novel your uncle was definitely going to finish — all .doc files. But there was a problem with these files.
They would become corrupted all of the goddamn time.
Remember, these were critical documents traveling from spinning rust drives on machines that crashed constantly compared to modern computers, often copied to floppy disks or later to cheap thumb drives you got from random vendor giveaways at conferences, and then carried to other computers in backpacks and coat pockets. The entire workflow had the structural integrity of a sandwich bag full of soup.
Your hard drive filesysystem -> your .doc file (which can get corrupted as a file) -> containers a mini filesystem (which can ALSO get corrupted internally) -> manages your actual document content
So when Word was saving your critical file, it was actually doing a bunch of different operations. It was:
Updating the document stream (your text)
Updating the formatting tables
Update the sector allocation tables
Update the directory entries
Update summary information
Flush everything to disk
These weren't atomic operations so it was super easy in an era when computers constantly crashed or had problems to end up in a situation where some structures were updated and others weren't. Compared to like a .txt file where you would either get the old version or a truncated new version. You might lose content, but you almost never ended up with an unreadable file. With .doc as someone doing like helpdesk IT, you constantly ended up with people that had just corrupted unreadable files.
And here's the part that really twisted the knife: the longer you worked on the same file, the more important that file likely was. But Word didn't clean up after itself. As a .doc accumulated images, tracked changes, and revision history, the internal structure grew more complex and the file got larger. But even when you deleted content from the document, the data wasn't actually removed from the file. It was marked as free space internally but left sitting there, like furniture you moved to the curb that nobody ever picked up.
The file bloated. The internal fragmentation worsened. And the probability of corruption increased in direct proportion to how much you cared about the contents.
Users had to be trained both to save the file often (as AutoRecover wasn't reliable enough) and to periodically "Save As" a new file to force Word to write a clean version from scratch. This was the digital equivalent of being told that your car works fine, you just need to rebuild the engine every 500 miles as routine maintenance.
The end result was that Microsoft Word quickly developed a reputation among technical people as horrible to work with. Not because it was a bad word processor — it was actually quite good at the word processing part — but because when a user showed up at the Help Desk with tears in their eyes, the tools I had to help them were mostly useless.
I could scan the raw file for text patterns, which often pulled out the content, but without formatting it wasn't really a recovered file — it was more like finding your belongings scattered across a field after a tornado. Technically your stuff, but not in any useful arrangement. Sometimes you could rebuild the FAT or try alternative directory entries to recover slightly older versions. But in general, if the .doc encountered a structural error, the thing was toast and your work was gone forever.
This led to a never-ending series of helpdesk sessions where I had to explain to people that yes, I understood they had worked on this file for months, but it was gone and nobody could help them. I became a grief counselor who happened to know about filesystems. Thankfully, people quickly learned to obsessively copy their files to multiple locations with different names — thesis_final.doc, thesis_final_v2.doc, thesis_FINAL_FINAL_REAL.doc — but this required getting burned at least once, which is sort of like saying you learned your car's brakes didn't work by driving into a bus.
Enter the XML Revolution
So around 2007 we see the shift from .doc to .docx, which introduces a lot of hard lessons from the problems of .doc. First, it's just a bundle, specifically a ZIP archive.
Now in theory, this is great. Your content is human-readable XML. Your images are just image files. If something goes wrong, you can rename the file to .zip, extract it, and at least recover your text by opening document.xml in Notepad. The days of staring at an opaque binary blob and praying were supposed to be over.
However, in practice, something terrible happened. Microsoft somehow managed to produce the worst XML to ever exist in human history.
Let me lay down the scope of this complexity, because I have never seen anything like it in my life.
Here is the standards website for ECMA-376. Now you know you are in trouble when you see a 4 part download that looks like the following:
Part 1 “Fundamentals And Markup Language Reference”, 5th edition, December 2016
Part 2 “Open Packaging Conventions”, 5th edition, December 2021
Part 3 “Markup Compatibility and Extensibility”, 5th edition, December 2015
Part 4 “Transitional Migration Features”, 5th edition, December 2016
If you download Part 1, you are given the following:
Now if you open that PDF, get ready for it. It's a 5039 page PDF.
I have never conceived of something this complicated. It's also functionally unreadable, and I say this as someone who has, on multiple occasions in his life, read a car repair manual cover to cover because I didn't have anything else to do. I once read the Haynes manual for a 1994 Honda Civic like it was a beach novel. This is not that. This is what happens when a standards committee gets a catering budget and no deadline.
Some light reading before bed
There was an accusation at the time that Microsoft was making OOXML deliberately more complicated than it needed to be — that the goal was to claim it was an "open standard" while making the standard so incomprehensibly vast that it would take a heroic effort for anyone else to implement it. I think this is unquestionably true. LibreOffice has a great blog post on it that includes this striking comparison:
The difference in complexity between the document.xml and content.xml files is striking when you compare their lengths: the content.xml file has 6,802 lines, while the document.xml file has 60,245 lines, compared to a text document of 5,566 lines.
So the difference between ODF format and the OOXML format results in a exponentially less complicated XML file. Either you could do the incredible amount of work to become compatible with this nightmarish specification or you could effectively find yourself cut out of the entire word processing ecosystem.
Now without question this was done by Microsoft in order to have their cake and eat it too. They would be able to tell regulators and customers that this wasn't a proprietary format and that nobody was locked into the Microsoft Office ecosystem for the production of documents, which had started to become a concern among non-US countries that now all of their government documents and records were effectively locked into using Microsoft. However the somewhat ironic thing is it ended up not mattering that much because soon the only desktop application that would matter is the browser.
Rise of Markdown
The file formats of word processors were their own problems, but more fundamentally the nature of how people consumed content was changing. Desktop based applications became less and less important post 2010 and users got increasingly more frustrated with the incredibly clunky way of working with Microsoft Word and all traditional files with emailing them back and forth endlessly or working with file shares.
So while .docx was a superior format from the perspective of "opening the file and it becoming corrupted", it also was fundamentally incompatible with the smartphone era. Even though you could open these files, soon the expectation was that whatever content you wanted people to consume should be viewable through a browser.
As "working for a software company" went from being a niche profession to being something that seemingly everyone you met did, the defacto platform for issues, tracking progress, discussions, etc moved to GitHub. This was where I (and many others) first encountered Markdown and started using it on a regular basis.
John Gruber, co-creator of Markdown, has a great breakdown of "standard" Markdown and then there are specific flavors that have branched off over time. You can see that here. The important part though is: it lets you very quickly generate webpages that work on every browser on the planet with almost no memorization and (for the most part) the same thing works in GitHub, on Slack, in Confluence, etc. You no longer had to ponder whether the person you were sending to had the right license to see the thing you were writing in the correct format.
This combined with the rise of Google Workspace with Google Docs, Slides, etc meant your technical staff were having conversations through Markdown pages and your less technical staff were operating entirely in the cloud. Google was better than Microsoft at the sort of stuff Word had always been used for, which is tracking revisions, handling feedback, sharing securely, etc. It had a small subset of the total features but as we all learned, nobody knew about the more advanced features of Word anyway.
By 2015 the writing was on the wall. Companies stopped giving me an Office license by default, switching them to "you can request a license". This, to anyone who has ever worked for a large company, is the kiss of death. If I cannot be certain that you can successfully open the file I'm working on, there is absolutely no point in writing it inside of that platform. Combine that with the corporate death of email and replacing it with Slack/Teams, the entire workflow died without a lot of fanfare.
Then with the rise of LLMs and their use (perhaps overuse) of Markdown, we've reached peak .md. Markdown is the format of our help docs, many of our websites are generated exclusively from Markdown. It's now the most common format that I write anything in. This was originally written in Markdown inside of Vim.
Why It Won
There's a lot of reasons why I think Markdown ended up winning, in no small part because it solved a real problem in an easy to understand way. Writing HTML is miserable and overkill for most tasks, this removed the need to do that and your output was consumable in a universal and highly performant way that required nothing of your users except access to a web browser.
But I also think it demonstrates an interesting lesson about formats. .doc and .docx along with ODF are pretty highly specialized things designed to handle the complexity of what modern word processing can do. LibreOffice lets you do some pretty incredible things that cover a huge range of possible needs.
Markdown doesn't do most of what those formats do. You can't set margins. You can't do columns. You can't embed a pivot table or track changes or add a watermark that says DRAFT across every page in 45-degree gray Calibri. Markdown doesn't even have a native way to change the font color.
And none of that mattered, because it turns out most writing isn't about any of those things. Most writing is about getting words down in a structure that makes sense, and then getting those words in front of other people. Markdown does that with less friction than anything else ever created. You can learn it in ten minutes, write it in any text editor on any device, read the source file without rendering it, diff it in version control, and convert it to virtually any output format.
The files are plain text. They will outlive every application that currently renders them. They don't belong to any company. They can't become corrupted in any meaningful way — the worst thing that can happen to a Markdown file is you lose some characters, and even then the rest of the file is fine. After decades of nursing .doc files like they were delicate flowers that you had to transport home strapped to your car roof, the idea of a format that simply cannot structurally fail is not just convenient. It's a kind of liberation.
I think about this sometimes when I'm writing in Vim at midnight, just me and a blinking cursor and a plain text file that will still be readable when I'm dead. No filesystem-within-a-filesystem. No sector allocation tables. No 5,039-page specification. Just words, a few hash marks, and never having to think about it again.