My first formal IT helpdesk role was basically "resetting stuff". I would get a ticket, an email or a phone call and would take the troubleshooting as far as I could go. Reset the password, check the network connection, confirm the clock time was right, ensure the issue persisted past a reboot, check the logs and see if I could find the failure event, then I would package the entire thing up as a ticket and escalate it up the chain.
It was effectively on the job training. We were all trying to get better at troubleshooting to get a shot at one of the coveted SysAdmin jobs. Moving up from broken laptops and desktops to broken servers was about as big as 22 year old me dreamed.
This is not what we looked like but how creepy is this photo?
Sometimes people would (rightfully) observe that they were spending a lot of time interacting with us, while the more senior IT people were working quietly behind us and they could probably fix the issue immediately. We would explain that, while that was true, our time was less valuable than theirs. Our role was to eliminate all of the most common causes of failure then to give them the best possible information to take the issue and continue looking at it.
There are people who understand waiting in a line and there are people who make a career around skipping lines. These VIPs encountered this flow in their various engineering organizations and decided that a shorter line between their genius and the cogs making the product was actually the "secret sauce" they needed.
Thus, Slack was born, a tool pitched to the rank and file as a nicer chat tool and to the leadership as a all-seeing eye that allowed them to plug directly into the nervous system of the business and get instant answers from the exact right person regardless of where they were or what they were doing.
My job as a professional Slacker
At first Slack-style chat seemed great. Email was slow and the signal to noise ratio was off, while other chat systems I had used before at work either didn't preserve state, so whatever conversation happened while you were offline didn't get pushed to you, or they didn't scale up to large conversations well. Both XMPP and IRC has the same issue, which is if you were there when the conversation was happening you had context, but otherwise no message history for you.
There were attempts to resolve this (https://xmpp.org/extensions/xep-0313.html) but support among clients was all over the place. The clients just weren't very good and were constantly going through cycles of intense development only to be abandoned. It felt like when an old hippie would tell you about Woodstock. "You had to be there, man".
Slack brought channels and channels bought a level of almost voyeurism into what other teams were doing. I knew exactly what everyone was doing all the time, down to I knew where the marketing team liked to go for lunch. Responsiveness became the new corporate religion and I was a true believer. I would stop walking in the hallway to respond to a DM or answer a question I knew the answer to, ignoring the sighs of frustration as people walked around my hoodie-clad roadblock of a body.
Sounds great, what's the issue?
So what's the catch? Well I first noticed it on the train. My daily commute home through the Chicago snowy twilight used to be a sacred ritual of mental decompression. A time to sift through the day's triumphs and (more often) the screw-ups. What needed fixing tomorrow? What problem had I pushed off maybe one day too long?
But as I got further and further into Slack, I realized I was coming home utterly drained yet strangely...hollow. I hadn't done any actual work that day.
My days had become a never-ending performance of "work". I was constantly talking about the work, planning the work, discussing the requirements of the work, and then in a truly Sisyphean twist, linking new people to old conversations where we had already discussed the work to get them up to speed on our conversation. All the while diligently monitoring my channels, a digital sentry ensuring no question went unanswered, no emoji not +1'd. That was it, that was the entire job.
Look I helped clean up (Martin Parr)
Show up, spend eight hours orchestrating the idea of work, and then go home feeling like I'd tried to make a sandcastle on the beach and getting upset when the tide did what it always does. I wasn't making anything, I certainly wasn't helping our users or selling the product. I was project managing, but poorly, like a toddler with a spreadsheet.
And for the senior engineers? Forget about it. Why bother formulating a coherent question for a team channel when you could just DM the poor bastard who wrote the damn code in the first place? Sure, they could push back occasionally, feigning busyness or pointing to some obscure corporate policy about proper channel etiquette. But let's be real. If the person asking was important enough (read: had a title that could sign off on their next project), they were answering. Immediately.
So, you had your most productive people spending their days explaining why they weren't going to answer questions they already knew the answer to, unless they absolutely had to. It's the digital equivalent of stopping a concert pianist to teach you "Twinkle Twinkle Little Star" 6 times a day.
It's a training problem too
And don't even get me started on the junior folks. Slack was actively robbing them of the chance to learn. Those small, less urgent issues? That's where the real education happens. You get to poke around in the systems, see how the gears grind, understand the delicate dance of interconnectedness. But why bother troubleshooting when Jessica, the architect of the entire damn stack, could just drop the answer into a DM in 30 seconds? People quickly figured out the pecking order. Why wait four hours for a potentially wrong answer when the Oracle of Code was just a direct message away?
You think you are too good to answer questions???
Au contraire! I genuinely enjoy feeling connected to the organizational pulse. I like helping people. But that, my friends, is the digital guillotine. The nice guys (and gals) finish last in this notification-driven dystopia. The jerks? They thrive. They simply ignore the incoming tide of questions, their digital silence mistaken for deep focus. And guess what? People eventually figure out who will respond and only bother those poor souls. Humans are remarkably adept at finding the path of least resistance, even if it leads directly to someone else's burnout.
Then comes review time. The jerk, bless his oblivious heart, has been cranking out code, uninterrupted by the incessant digital demands. He has tangible projects to point to, gleaming monuments to his uninterrupted focus. The nice person, the one everyone loves, the one who spent half their day answering everyone else's questions? Their accomplishments are harder to quantify. "Well, they were really helpful in Slack..." doesn't quite have the same ring as "Shipped the entire new authentication system."
It's the same problem with being the amazing pull request reviewer. Your team appreciates you, your code quality goes up, you’re contributing meaningfully. But how do you put a number on "prevented three critical bugs from going into production"? You can't. So, you get a pat on the back and maybe a gift certificate to a mediocre pizza place.
Slackifying Increases
Time marches on, and suddenly, email is the digital equivalent of that dusty corner in your attic where you throw things you don't know what to do with. It's a wasteland of automated notifications from systems nobody cares about. But Slack? There’s no rhyme or reason to it. Can I message you after hours with the implicit understanding you'll ignore it until morning? Should I schedule the message for later, like some passive-aggressive digital time bomb?
And the threads! Oh, the glorious, nested chaos of threads. Should I respond in a thread to keep the main channel clean? Or should I keep it top-level so that if there's a misunderstanding, the whole damn team can pile on and offer their unsolicited opinions? What about DMs? Is there a secret protocol there? Or is it just a free-for-all of late-night "u up?" style queries about production outages?
It felt like every meeting had a pre-meeting in Slack to discuss the agenda, followed by an actual meeting on some other platform to rehash the same points, and then a post-meeting discussion in a private channel to dissect the meeting itself. And inevitably, someone who missed the memo would then ask about the meeting in the public channel, triggering a meta-post-meeting discussion about the pre-meeting, the meeting, and the initial post-meeting discussion.
The only way I could actually get any work done was to actively ignore messages. But then, of course, I was completely out of the loop. The expectation became this impossible ideal of perfect knowledge, of being constantly aware of every initiative across the entire company. It was like trying to play a gameshow and write a paper at the same time. To be seen as "on it", I needed to hit the buzzer and answer the question, but come review time none of those points mattered and the scoring was made up.
I was constantly forced to choose: stay informed or actually do something. If I chose the latter, I risked building the wrong thing or working with outdated information because some crucial decision had been made in a Slack channel I hadn't dared to open for fear of being sucked into the notification vortex. It started to feel like those brief moments when you come up for air after being underwater for too long. I'd go dark on Slack for a few weeks, actually accomplish something, and then spend the next week frantically trying to catch up on the digital deluge I'd missed.
Attention has a cost
One of the hardest lessons for anyone to learn is the profound value of human attention. Slack is a fantastic tool for those who organize and monitor work. It lets you bypass the pesky hierarchy, see who's online, and ensure your urgent request doesn't languish in some digital abyss. As an executive, you can even cut out middle management and go straight to the poor souls actually doing the work. It's digital micromanagement on steroids.
But if you're leading a team that's supposed to be building something, I'd argue that Slack and its ilk are a complete and utter disaster. Your team's precious cognitive resources are constantly being bled dry by a relentless stream of random distractions from every corner of the company. There are no real controls over who can interrupt you or how often. It's the digital equivalent of having your office door ripped off its hinges and replaced with glass like a zoo. Visitors can come and peer in on what your team is up to.
Turns out, the lack of history in tools like XMPP and IRC wasn't a bug, it was a feature. If something important needed to be preserved, you had to consciously move it to a more permanent medium. These tools facilitated casual conversation without fostering the expectation of constant, searchable digital omniscience.
Go look at the Slack for any large open-source project. It's pure, unadulterated noise. A cacophony of voices shouting into the void. Developers are forced to tune out, otherwise it's all they'd do all day. Users have a terrible experience because it's just a random stream of consciousness, people asking questions to other people who are also just asking questions. It's like replacing a structured technical support system with a giant conference call where everyone is on hold and told to figure it out amongst themselves.
My dream
So, what do I even want here? I know, I know, it's a fool's errand. We're all drowning in Slack clones now. You can't stop this productivity-killing juggernaut. It's like trying to un-ring a bell, or perhaps more accurately, trying to silence a thousand incessantly pinging notifications.
But I disagree. I still think it's not too late to have a serious conversation about how many hours a day it's actually useful for someone to spend on Slack. What do you, as a team, even want out of a chat client? For many teams, especially smaller ones, it makes far more sense to focus your efforts where there's a real payoff. Pick one tool, one central place for conversations, and then just…turn off the rest. Everyone will be happier, even if the tool you pick has limitations, because humans actually thrive within reasonable constraints. Unlimited choice, as it turns out, is just another form of digital torture.
Try to get away with the most basic, barebones thing you can for as long as you can. I knew a (surprisingly productive) team that did most of their conversation on an honest-to-god phpBB internal forum. Another just lived and died in GitHub with Issues. Just because it's a tool a lot of people talk about doesn't make it a good tool and just because it's old, doesn't make it useless.
As for me? I'll be here, with my Slack and Teams and Discord open trying to see if anything has happened in any of the places I'm responsible for seeing if something has happened. I will consume gigs of RAM on what, even ten years ago, would have been an impossibly powerful computer to watch basically random forum posts stream in live.
Anybody who has worked in a tech stack of nearly any complexity outside of Hello World is aware of the problems with the current state of the open-source world. Open source projects, created by individuals or small teams to satisfy a specific desire they have or problem they want to solve, are adopted en masse by large organizations whose primary interest in consuming them are saving time and/or money. These organizations rarely contribute back to these projects, creating a chain of critical dependencies that are maintained inconsistently.
Similar to if your general contractor got cement from a guy whose hobby was mixing cement, the results are (understandably) all over the place. Sometimes the maintainer does a great job for awhile then gets bored or burned out and leaves. Sometimes the project becomes important enough that a vanishingly small percentage of the profit generated by the project is redirect back towards it and a person can eek out a meager existence keeping everything working. Often they're left in a sort of limbo state, being pushed forward by one or two people while the community exists in a primarily consumption role. Whatever stuff these two want to add or PRs they want to merge is what gets pushed in.
In the greater tech community, we have a lot of conversations about how we can help maintainers. Since a lot of the OSS community trends towards libertarian, the vibe is more "how can we encourage more voluntary non-mandated assistance towards these independent free agents for whom we bare no responsibility and who have no responsibility towards us". These conversations go nowhere because the idea of a widespread equal distribution of resources based on value without an enforcement mechanism is a pipe dream. The basic diagram looks like this:
+---------------------------------------------------------------+
| |
| "We need to support open-source maintainers better!" |
| |
+---------------------------------------------------------------+
|
v
+---------------------------------------------------------------+
| |
| "Let's have a conference to discuss how to help them!" |
| |
+---------------------------------------------------------------+
|
v
+---------------------------------------------------------------+
| |
| "We should provide resources without adding requirements." |
| |
+---------------------------------------------------------------+
|
v
+---------------------------------------------------------------+
| |
| "But how do we do that without more funding or time?" |
| |
+---------------------------------------------------------------+
|
v
+---------------------------------------------------------------+
| |
| "Let's ask the maintainers what they need!" |
| |
+---------------------------------------------------------------+
|
v
+---------------------------------------------------------------+
| |
| Maintainers: "We need more support and less pressure!" |
| |
+---------------------------------------------------------------+
|
v
+---------------------------------------------------------------+
| |
| "Great! We'll discuss this at the next conference!" |
| |
+---------------------------------------------------------------+
|
v
+---------------------------------------------------------------+
| |
| "We need to support open-source maintainers better!" |
| |
+---------------------------------------------------------------+
I've already read this post a thousand times
So we know all this. But as someone who uses a lot of OSS and (tries) to provide meaningful feedback and refinements back to the stuff I use, I'd like to talk about a different problem. The problem I'm talking about is how hard it is to render assistance to maintainers. Despite endless hours of people talking about how we should "help maintainers more", it's never been less clear what that actually means.
I, as a person, have a finite amount of time on this Earth. I want to help you, but I need the process to help you to make some sort of sense. It also has to have some sort of consideration for my time and effort. So I'd like to propose just a few things I've run into over the last few years I'd love if maintainers could do just to help me be of service to you.
If you don't want PRs, just say that. It's fine, but the number of times I have come across projects with a ton of good PRs just sitting there is alarming. Just say "we don't merge in non-maintainers PRs" and move on.
Don't automatically close bug reports. You are under zero ethical obligation to respond to or solve my bug report. But at the very least, don't close it because nobody does anything with it for 30 days. Time passing doesn't make it less real. There's no penalty for having a lot of open bug reports.
If you want me to help, don't make me go to seven systems. The number of times I've opened an issue on GitHub only to then have to discuss it on Discord or Slack and then follow-up with someone via an email is just a little maddening. If your stuff is on GitHub do everything there. If you want to have a chat community, fine I guess, but I don't want to join your tech support chat channel.
Archive when you are done. You don't need to explain why you are doing this to anyone on Earth, but if you are done with a project archive it and move on. You aren't doing any favors by letting it sit forever collecting bug reports and PRs. Archiving it says "if you wanna fork this and take it over, great, but I don't want anything to do with it anymore".
Provide an example of how you want me to contribute. Don't say "we prefer PRs with tests". Find a good one, one that did it the right way and give me the link to it. Or make it yourselves. I'm totally willing to jump through a lot of hoops for the first part, but it's so frustrating when I'm trying to help and the response is "well actually what we meant by tests is we like things like this".
If you have some sort of vision of what the product is or isn't, tell me about it. This comes up a lot when you go to add a feature that seems pretty obvious only to have the person close it with an exhausted response of "we've already been over this a hundred times". I understand this is old news to you, but I just got here. If you have stuff that comes up a lot that you don't want people to bother you with, mention it in the README. I promise I'll read it and I won't bother you!
If what you want is money, say that. I actually prefer when a maintainer says something like "donors bug reports go to the front of the line" or something to that effect. If you are a maintainer who feels unappreciated and overwhelmed, I get that and I want to work with you. If the solution is "my organization pays you to look at the bug report first", that's totally ethnically acceptable. For some reason this seems icky to the community ethos in general, but to me it just makes sense. Just make it clear how it works.
If there are tasks you think are worth doing but don't want to do, flag them. I absolutely love when maintainers do this. "Hey this is a good idea, it's worth doing, but it's a lot of work and we don't want to do it right now". It's the perfect place for someone to start and it hits that sweet spot of high return on effort.
I don't want this to read like "I, an entitled brat, believe that maintainers owe me". You provide an amazing service and I want to help. But part of helping is I need to understand what is it that you would like me to do. Because the open-source community doesn't adopt any sort of consistent cross-project set of guidelines (see weird libertarian bent) it is up to each one to tell me how they'd like to me assist them.
But I don't want to waste a lot of time waiting for a perfect centralized solution to this problem to manifest. It's your project, you are welcome to do with it whatever you want (including destroy it), but if you want outside help then you need to sit down and just walk through the question of "what does help look like". Tell me what I can do, even if the only thing I can do is "pay you money".
One of the biggest hurdles for me when trying out a new service or product is the inevitable harassment that follows. It always starts innocuously:
“Hey, I saw you were checking out our service. Let me know if you have any questions!”
Fine, whatever. You have documentation, so I’m not going to email you, but I understand that we’re all just doing our jobs.
Then, it escalates.
“Hi, I’m your customer success fun-gineer! Just checking in to make sure you’re having the best possible experience with your trial!”
Chances are, I signed up to see if your tool can do one specific thing. If it doesn’t, I’ve already mentally moved on and forgotten about it. So, when you email me, I’m either actively evaluating whether to buy your product, or I have no idea why you’re reaching out.
And now, I’m stuck on your mailing list forever. I get notifications about all your new releases and launches, which forces me to make a choice every time:
• “Obviously, I don’t care about this anymore.”
• “But what if they’ve finally added the feature I wanted?”
Since your mailing list is apparently the only place on Earth to find out if Platform A has added Feature X (because putting release notes somewhere accessible is apparently too hard), I have to weigh unsubscribing every time I see one of your marketing emails.
And that’s not even the worst-case scenario. The absolute worst case is when, god forbid, I can actually use your service, but now I’m roped into setting up a “series of calls.”
You can't just let me input a credit card number into a web site. Now I need to form a bunch of interpersonal relationships with strangers over Microsoft Teams.
Let's Jump On A Call
Every SaaS sales team has this classic duo.
First, there’s the salesperson. They’re friendly enough but only half paying attention. Their main focus is inputting data into the CRM. Whether they’re selling plastic wrap or missiles, their approach wouldn’t change much. Their job is to keep us moving steadily toward The Sale.
Then, there’s their counterpart: the “sales engineer,” “customer success engineer,” or whatever bastardized title with the word engineer they’ve decided on this week. This person is one of the few people at the company who has actually read all the documentation. They’re brought in to explain—always with an air of exhaustion—how this is really my new “everything platform.”
“Our platform does everything you could possibly want. We are very secure—maybe too secure. Our engineers are the best in the world. Every release is tested through a 300-point inspection process designed by our CTO, who interned at Google once, so we strongly imply they held a leadership position there.”
I will then endure a series of demos showcasing functionality I’ll never use because I’m only here for one or two specific features. You know this, but the rigid demo template doesn’t allow for flexibility, so we have to slog through the whole thing.
To placate me, the salesperson will inevitably say something like,
“Mat is pretty technical—he probably already knows this.”
As if this mild flattery will somehow make me believe that a lowly nerd like me and a superstar salesperson like you could ever be friends. Instead, my empathy will shift to the sales engineer, whose demo will, without fail, break at the worst possible time. Their look of pure despair will resonate with me deeply.
“Uh, I promise this normally works.”
There, there. I know. It’s all held together with tape and string.
At some point, I’ll ask about compliance and security, prompting you to send over a pile of meaningless certifications. These documents don’t actually prove you did the things outlined in them; they just demonstrate that you could plausibly fake having done them.
We both know this. If I got you drunk, you’d probably tell me horror stories about engineers fixing databases by copying them to their laptops, or how user roles don’t really work and everyone is secretly an admin.
But this is still the dating phase of our relationship, so we’re pretending to be on our best behavior.
We’ve gone through the demos. You’ve tried to bond with me, forming a “team” that will supposedly work together against the people who actually matter and make decisions at my company. Now you want to bring my boss’s boss into the call to pitch them directly.
Here’s the problem: that person would rather be set on fire than sit through 12 of these pitches a week from various companies. So, naturally, it becomes my job to “put together the proposal.”
This is where things start to fall apart. The salesperson grows increasingly irritated because they could close the deal if they didn’t have to talk to me and could just pitch directly to leadership. Meanwhile, the sales engineer—who, for some reason, is still forced to attend these calls—stares into the middle distance like an orphan in a war zone.
“Look, can we just loop in the leadership on your side and wrap this up?” the salesperson asks, visibly annoyed.
“They pay me so they don’t have to talk to you,” I’ll respond, a line you first thought was a joke but have since realized was an honest admission you refused to hear early in our relationship.
If I really, really care about your product, I’ll contact the 300 people I need on my side to get it approved. This process will take at least a month. Why? Who knows—it just always does. If I work for a Fortune 500 company, it’ll take a minimum of three months, assuming everything goes perfectly.
By this point, I hate myself for ever clicking that cursed link and discovering your product existed. What was supposed to save me time has now turned into a massive project. I start to wonder if I should’ve just reverse-engineered your tool myself.
Eventually, it’s approved. Money is exchanged, and the salesperson disappears forever. Now, I’m handed off to Customer Service—aka a large language model (LLM).
The Honeymoon Is Over
It doesn’t take long to realize that your “limitless, cloud-based platform designed by the best in the business” is, in fact, quite limited. One day, everything works fine. The next, I unknowingly exceed some threshold, and the whole thing collapses in on itself.
I’ll turn to your documentation, which has been meticulously curated to highlight your strengths—because god forbid potential customers see any warnings. Finding no answers, I’ll engage Customer Service. After wasting precious moments of my life with an LLM that links me to the same useless documentation, I’ll finally be allowed to email a real person.
The SLA on that support email will be absurdly long—72 business hours—because I didn’t opt for the Super Enterprise Plan™. Eventually, I’ll get a response explaining that I’ve hit some invisible limit and need to restructure my workflows to avoid it.
As I continue using your product, I’ll develop a growing list of undocumented failure modes:
“If you click those two buttons too quickly, the iFrame throws an error.”
I’ll actually say this to another human being, as if we’re in some cyberpunk dystopia where flying cars randomly explode in the background because they were built by idiots. Despite your stack presumably logging these errors, no one will ever reach out to explain them or help me fix anything.
Account Reps
Then, out of the blue, I’ll hear from my new account rep. They’ll want a call to “discuss how I’m using the product” and “see how they can help.” Don’t be fooled—this isn’t an attempt to gather feedback or fix what’s broken. It’s just another sales pitch.
After listening to my litany of issues and promising to “look into them,” the real purpose of the call emerges: convincing me to buy more features. These “new features” are things that cost you almost nothing but make a huge difference to me—like SSO or API access. Now I’m forced to decide whether to double down on your product or rip it out entirely and move on with my life.
Since it’s not my money, I’ll probably agree to give you more just to get basic functionality that should’ve been included in the first place.
Fond Farewell
Eventually, one of those open-source programmers—the kind who gleefully release free tools and then deal with endless complaints for life—will create something that does what your product does. It’ll have a ridiculous name like CodeSquish, Dojo, or GitCharm.
I’ll hear about it from a peer. When I mention I use your product, they’ll turn to me, eyes wide, and say, “Why don’t you just use CodeSquish?”
Not wanting to admit ignorance, I’ll make up a reason on the spot. Later, in the bathroom, I’ll Google CodeSquish and discover it does everything I need, costs nothing, and is 100x more performant—even though it’s maintained by a single recluse who only emerges from their Vermont farm to push code to their self-hosted git repo.
We’ll try it out. Despite the fact that its only “forum” is a Discord server, it’ll still be miles ahead of your commercial product.
Then comes the breakup. I’ll put it off for as long as possible because we probably signed a contract. Eventually, I’ll tell Finance not to renew it. Suddenly, I’ll get a flurry of attention from your team. You’ll pitch me on why the open-source tool is actually inferior (which we both know isn’t true).
I’ll tell you, “We’ll discuss it on our side.” We won’t. The only people who cared about your product were me and six others. Finally, like the coward I am, I’ll break up with you over email—and then block your domain.
I've complained a lot about the gaps in offerings for login security in the past. The basic problem is this domain of security serves a lot of masters. To get the widest level of buy-in from experts, the solution has to scale from normal logins to national security. This creates a frustrating experience for users because it is often overkill for the level of security they need. Basically is it reasonable that you need Google Authenticator to access your gym website? In terms of communication, the solutions we hear about the most, i.e. with the most marketing, allow for the insertion of SaaS services into the chain so that an operation that was previously free now pays a monthly fee based on usage.
This creates a lopsided set of incentives where only the most technologically complex and extremely secure solutions are endorsed and when teams are (understandably) overwhelmed by their requirements a SaaS attempts to get inserted into a critical junction of their product.
The tech community have mostly agreed that username and passwords assigned by the user are not sufficient for even basic security. What we haven't done is precisely explained what it is that we want normal average non-genius developers to do about that. We've settled on this really weird place with the following rules:
Email accounts are always secure but SMS is never secure. You can always email a magic link and that's fine for some reason.
You should have TOTP but we've settled on very short time windows because I guess we decided NTP was a solved problem. There's no actual requirement the code changes every 30 seconds, we're just pretending that we're all spies and someone is watching your phone. Also consumers should be given recovery codes, which are basically just passwords you generate and give to them and only allow to be used once. It is unclear why generating a one-time password for the user is bad but if we call the password a "recovery code" it is suddenly sufficient.
TOTP serves two purposes. One is it ensures there is one randomly generated secret associated with the account that we don't hash (even though I think you could....but nobody seems to), so it's actually kind of a dangerous password that we need to encrypt and can't rotate. The other is we tacked on this stupid idea that it is multi-device, even though there's zero requirement that the code lives on another device. Just someone decided that because there is a QR code it is now multi-device because phones scan QR codes.
At some point we decided to add a second device requirement, but those devices live in entirely different ecosystems. Even if you have an iPhone and a work MacBook, they shouldn't be using the same Apple ID, so I'm not really clear how things would ever line up. It seems like most people sync things like TOTP with their personal Google accounts across different work devices over time. I can't imagine that was the intended functionality.
Passkeys are great but also their range of behavior is bizarre and unpredictable so if you implement them you will be expected to effectively build every other possible recovery flow into this system. Even highly technical users cannot be relied upon to know whether they will lose their passkey when they do something.
Offloading the task to a large corporation is good, but you cannot pick one big corporation. You must have a relationship with Apple and Facebook and Microsoft and Google and Discord and anyone else who happens to be wandering around when you build this. Their logins are secured with magic and unbreakable, but if they are bypassed you can go fuck yourself because that is your problem, not theirs.
All of this is sort of a way to talk around the basic problem. I need a username and a password for every user on my platform. That password needs to be randomly generated and never stored as plain text in my database. If I had a way to know that the browser generated and stored the password, this basic level of security is met. As far as I can tell, there's no way for me to know that for sure. I can guess based on the length of the password and how quickly it was entered into a form field.
Keep in mind all I am trying to do is build a simple login route on an application that is portable, somewhat future proof and doesn't require a ton of personal data from the user to resolve common human error problems. Ideally I'd like to be able to hand this to someone else, they generate a new secret and they too can enroll as many users as they want. This is a simple thing to build so it should be simple to solve the login story as well.
Making a simple CMS
The site you are reading this on is hosted on Ghost, a CMS that is written in Node. It supports a lot of very exciting features I don't use and comes with a lot of baggage I don't need. Effectively all I actually use for is:
RSS
Writing posts in its editor
Fixing typos in the posts I publish (sometimes, my writing is not good)
Let me write a million drafts for every thing I publish
Minimize the amount of JS I'm inflicting on people and try whenever possible to stick to just HTML and CSS
Ghost supports a million things on top of the things I have listed and it also comes with some strange requirements like running MySQL. I don't really need a lot of that stuff and running a full MySQL for a CMS that doesn't have any sort of multi-instance scaling functionality seems odd. I also don't want to stick something this complicated on the internet for people to use for long periods of time without regular maintenance.
Before you say it I don't care for static site generators. I find it's easier for me to have a tab open, write for ten minutes, then go back to what I was doing before.
My goal with this is just to make a normal friendly baby CMS that I could share with a group of people, less technical people, so they could write stuff when they felt like it. We're not trading nuclear secrets here. The requirements are:
Needs to be open to the public internet with no special device enrollment or network segmentation
Not administered by me. Whatever normal problem arises it has to be solvable by a non-technical person.
Making the CMS
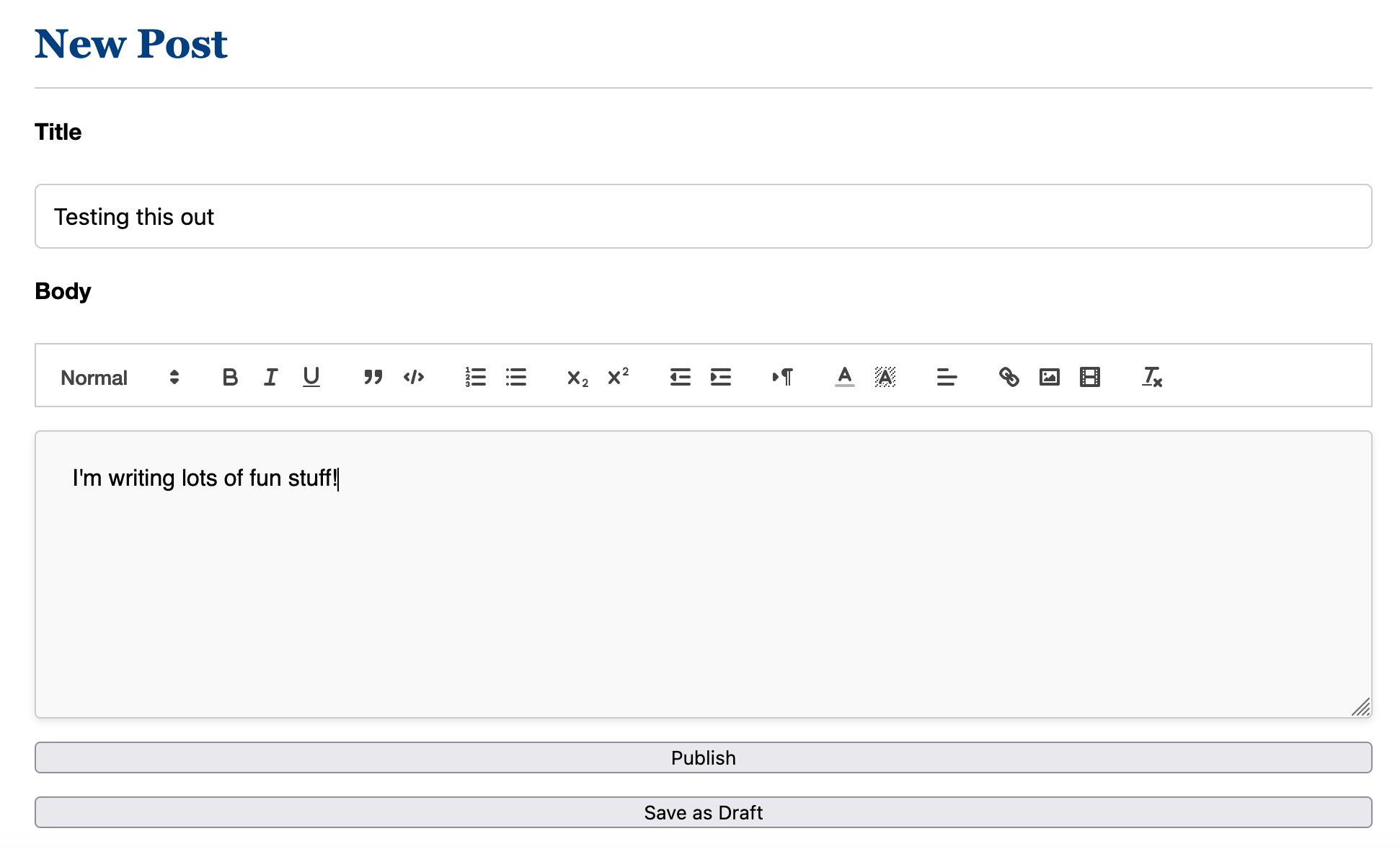
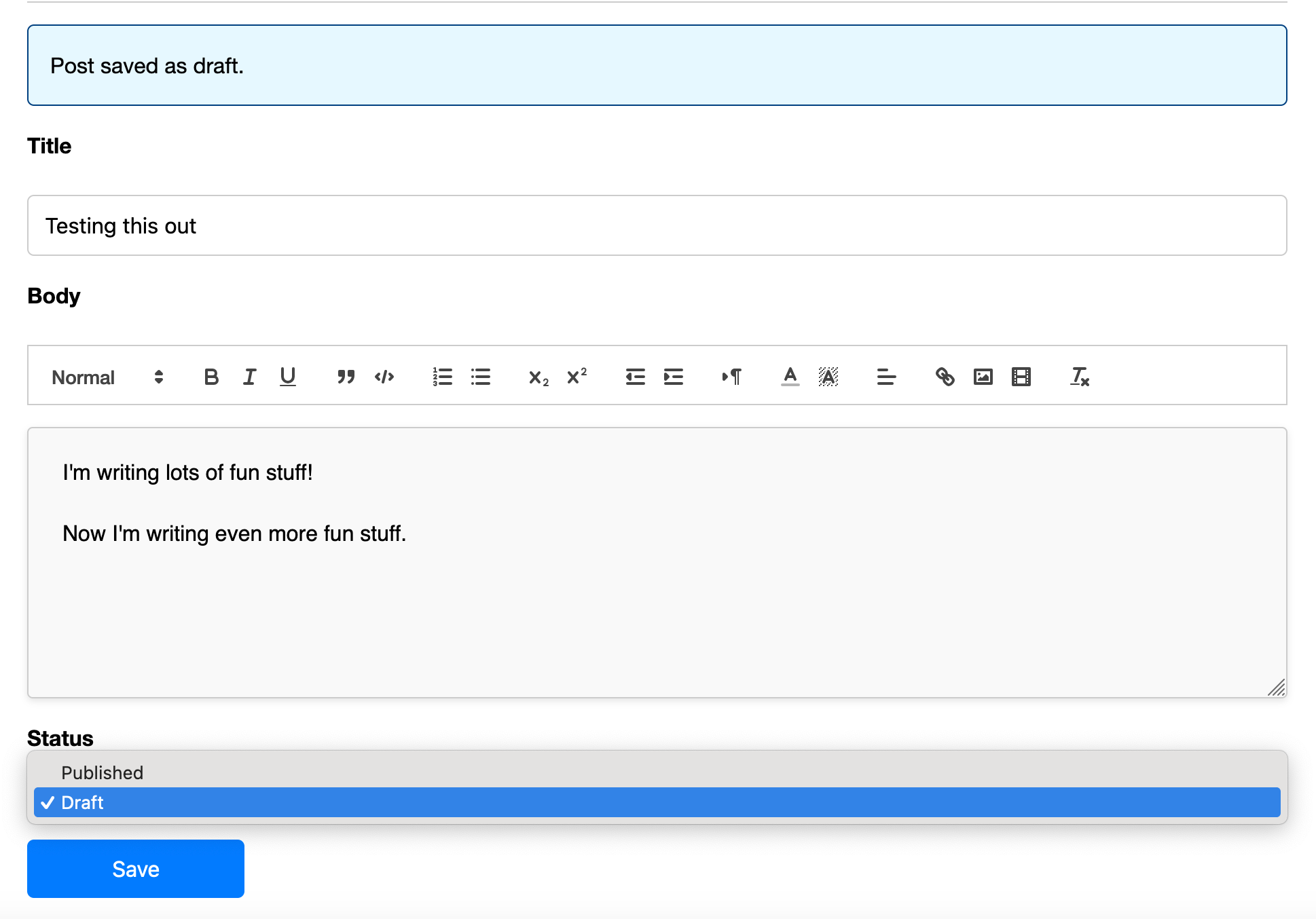
So in a day when I was doing other stuff I put this together: https://gitlab.com/matdevdug/ezblog. It's nothing amazing, just sort of a basic template I can build on top of later. Uses sqlite and it does the things you would expect it to do. I can:
Write posts in Quill
Save the posts as drafts or as published posts
Edit the posts after I publish them
Have a valid RSS feed of the posts
The whole frontend is just HTML/CSS so it'll load fast and be easy to cache
Then there is the whole workflow of draft to published.
For one days work this seems to be roughly where I hoped to be. Now we get to the crux of the matter. How do I log in?
What you built is bad and I hate it
The point is I should be able to solve this problem quickly and easily for a hobby website, not that you personally like what I made. The examples are not fully-fleshed out examples, just templates to demonstrate the problem. Also I'm allowed to make stuff that serves no other function than it amuses me.
Password Login
The default for most sites (including Ghost) is just a username and password. The reason for this: it's easy, works on everything and it's pretty simple to work out a fallback flow for users. Everyone understands it, there's no concerns around data ownership or platform lock-in.
I've got a csrf_token in there and the rest is pretty straight forward. Server-side is also pretty easy.
@bp.route('/login', methods=('GET', 'POST'))
@limiter.limit("5 per minute")
def login():
if request.method == 'POST':
username = request.form['username']
password = request.form['password']
db = get_db()
error = None
user = db.execute(
'SELECT * FROM user WHERE username = ?', (username,)
).fetchone()
if user is None:
error = 'Incorrect username.'
elif not check_password_hash(user['password'], password):
error = 'Incorrect password.'
if error is None:
session.clear()
session['user_id'] = user['id']
return redirect(url_for('index'))
flash(error)
return render_template('auth/login.html')
I'm not storing the raw password, just the hash. It's requires almost no work to do. It works exactly the way I think it should. Great fine.
Why are passwords insufficient?
This has been talked to death but let's recap for the sake of me being able to say I did it and you can just kinda scroll quickly through this part.
Users reuse usernames and passwords, so even though I might not know the raw text of the password another website might be (somehow) even lazier than me and their database gets leaked and then oh no I'm hacked.
The password might be a bad password and it's just one people try and oh no they are in the system.
I have to build in a password reset flow because humans are bad at remembering things and that's just how it is.
Password Reset Flow
Everyone has seen this, but let's talk about what I would need to modify about this small application to allow more than one person to use it.
I would need to add a route that handles allowing the user to reset their password by requesting it through their email
To know where to send that email, I would need to receive and store the email address for every user
I would also need to verify the users email to ensure it worked
All of this hinges on having a token I could send to that user that I could generate with something like the following:
Since I'm salting it with the hash of the current password which will change when they change the password, the token can only be used once. Makes sense.
Why is this bad?
For a ton of reasons.
I don't want to know an email address if I don't need it. There's no reason to store more personal information about a user that makes the database more valuable if someone were to steal it.
Email addresses change. You need to write another route which handles that process, which isn't hard but then you need to decide whether you need to confirm that the user has access to address 1 with another magic URL or if it is sufficient to say they are currently logged in.
Finally it sort of punts the problem to email and says "well I assume and hope your email is secure even if statistically you probably use the same password for both".
How do you fix this?
The problem can be boiled down to 2 basic parts:
I don't want the user to tell me a username, I want a randomly generated username so it further reduces the value of information stored in my database. It also makes it harder to do a random drive-by login attempt.
I don't want to own the password management story. Ideally I want the browser to do this on its side.
In a perfect world I want a response that says "yes we have stored these credentials somewhere under this users control" and I can wash my hands of that until we get into the situation where somehow they've lost access to the sync account (which should hopefully be rare enough that we can just do that in the database).
The annoying thing is this technology already exists.
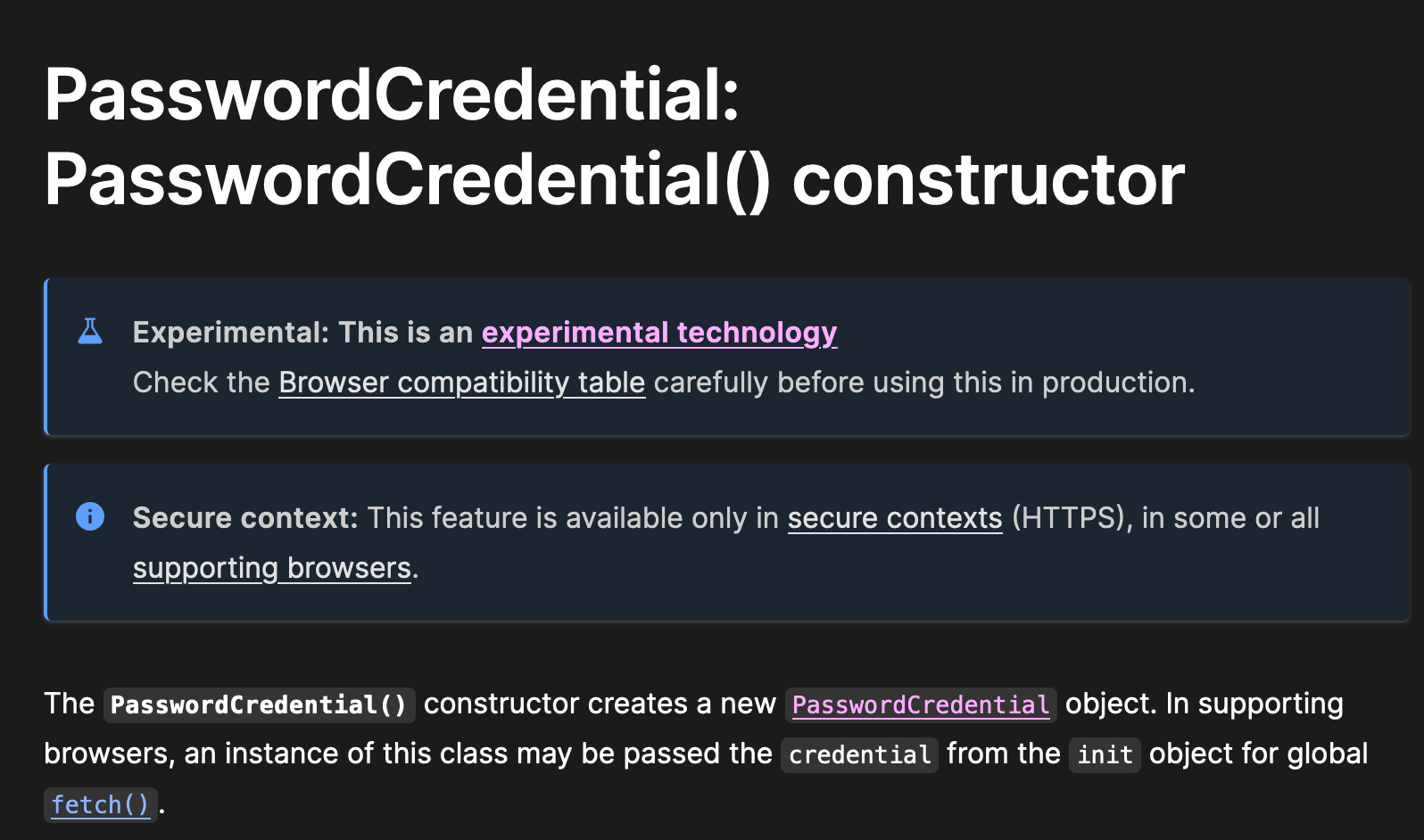
The Credential Manager API does the things I am talking about. Effectively I would need to add some Javascript to my Registration page:
<script>
document.getElementById('register-form').addEventListener('submit', function(event) {
event.preventDefault(); // Prevent form submission
const username = document.getElementById('username').value;
const password = document.getElementById('password').value;
// Save credentials using Credential Management API
if ('credentials' in navigator) {
const cred = new PasswordCredential({
id: username,
password: password
});
// Store credentials in the browser's password manager
navigator.credentials.store(cred).then(() => {
console.log('Credentials stored successfully');
// Proceed with registration, for example, send credentials to your server
registerUser(username, password);
}).catch(error => {
console.error('Error storing credentials:', error);
});
}
});
function registerUser(username, password) {
// Simulate server registration request
fetch('/register', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ username: username, password: password })
}).then(response => {
if (response.ok) {
console.log('User registered successfully');
// Redirect or show success message
} else {
console.error('Registration failed');
}
});
}
</script>
Then on my login page something like this:
function attemptAutoLogin() {
if ('credentials' in navigator) {
navigator.credentials.get({password: true}).then(cred => {
if (cred) {
// Send the credentials to the server to log in the user
fetch('/login', {
method: 'POST',
body: new URLSearchParams({
'username': cred.id,
'password': cred.password
})
}).then(response => {
// Handle login success or failure
if (response.ok) {
console.log('User logged in');
} else {
console.error('Login failed');
}
});
}
}).catch(error => {
console.error('Error retrieving credentials:', error);
});
}
}
// Call the function when the page loads
document.addEventListener('DOMContentLoaded', attemptAutoLogin);
So great, I assign a random cred.id and cred.password, stick it in the browser and then I sorta wash my hands of it.
We know the password is stored somewhere and can be synced for free
We know the user can pull the password out and put it somewhere else if they want to switch platforms
Browsers handle password migrations for users
The problem with this approach is I don't know if I'm supposed to use it.
I have no idea what this means. Could this go away? In testing it does seem like the performance is all over the place. Firefox seems to have some issues with this, whereas Chrome seems to always nail it. iOS Safari also seems to have some problems. So this isn't seemingly reliable enough to use.
Just please just make this a thing that works everywhere.
Before you yell at me about Math.random I think the following would make a good password:
function generatePassword(length) {
const charset = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789";
let password = "";
for (let i = 0; i < length; i++) {
const randomIndex = Math.floor(Math.random() * charset.length);
password += charset.charAt(randomIndex);
}
return password;
}
const password = generatePassword(32);
console.log(password);
Alright so I can't get away with just a password, so I have to assume the password is bunk and use it as one element of login. Then I have to use either TOTP or HOTP.
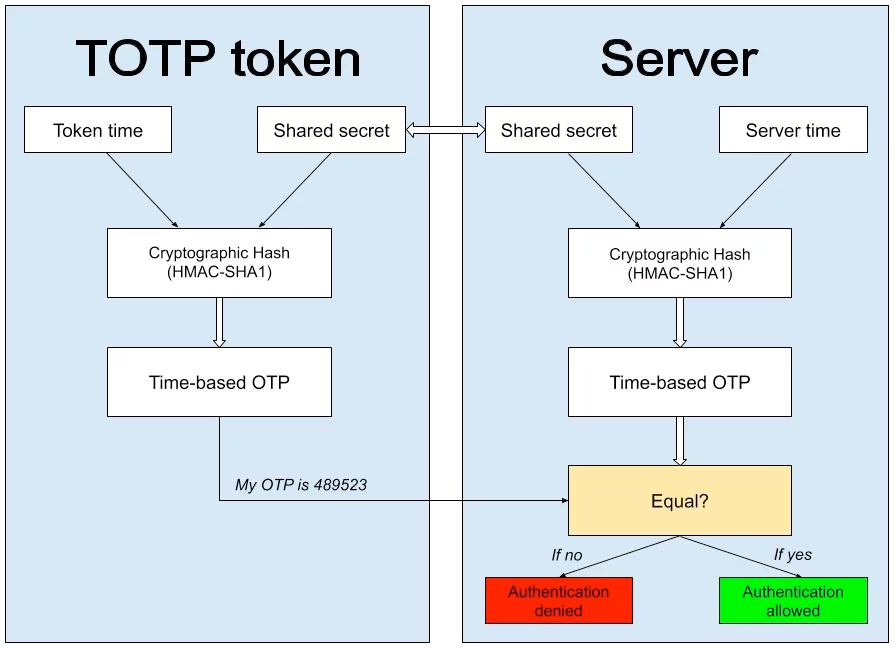
From a user perspective TOTP works as follows:
Set up 2FA for your online account.
Get a QR code.
You scan this QR code with an authenticator app of your choice
Your app will immediately start generating these six-digit tokens.
The website asks you to provide one of these six-digit tokens.
Practically this is pretty straight forward. I add a few extra libraries:
import io
import pyotp
import qrcode
from flask import send_file
I have to generate a secret totp_secret = pyotp.random_base32() which then I have to store in the database. Then I have to generate a QR code to show the user so they can generate the time-based codes.
However the more you look into this, the more complicated it gets.
You actually don't need the token to be 6 digits. It can be up to 10. I don't know why I'd want more or less. Presumably more is better.
The token can be valid for longer than 30 seconds. From reading it seems like that makes the code less reliant on perfect time sync between client and server (great) but also increases the probability of someone stealing the TOTP and using it. That doesn't seem like a super likely attack vector here so I'll make it way longer. But then why don't more services use longer tokens if the only concern then is if someone sees my code? Is this just people being unspeakably annoying?
I need to add some recovery step in case you lose access to the TOTP code.
How do you recover from a TOTP failure?
Effectively I'm back to my original problem. I can either:
Go back to the email workflow I don't want because again I don't want to rely on email as some sort of super-secure bastion and I really don't want to store email addresses.
Or I generate a recovery code and give you those codes which let you bypass the TOTP requirement. That at least lets me be like "this is no longer my fault". I like that.
How do I make a recovery code?
Honest to god I have no idea. As far as I can tell a "recovery code" is just a randomly generated value I hash and stick in the database and then when the user enters it on a form, check the hash. It's just another password. I don't know why all the recovery codes I see are numbers, since it seems to have no relationship to that and would likely work with any string.
Effectively all I need to do with the recovery code is ensure it gets burned once used. Which is fine, but now I'm confused. So I'm generating passwords for the user and then I give the passwords back to the user and tell them to store them somewhere? Why don't I just give them the one good password for the initial login and call it a day? Why is one forbidden and the other is mandatory?
Does HOTP help?
I'm really still not clear how HOTP works. Like I understand the basics:
@app.route('/verify_2fa', methods=['GET', 'POST'])
def verify_2fa():
if request.method == 'POST':
hotp = pyotp.HOTP(user_data['hotp_secret'])
otp = request.form['otp']
if hotp.verify(otp, user_data['counter']):
user_data['counter'] += 1 # Increment the counter after successful verification
return redirect(url_for('index'))
flash('Invalid OTP')
return render_template('verify_2fa.html')
There is a secret per-user and a counter and then I increment the counter every single time the user logs in. As far as I can tell there isn't a forcing mechanism which keeps the client and the server in-sync, so basically you tap a button and generate a password and then if you accidentally tap the button again the two counters are off. It seems like then the server has to decide "are you a reasonable number of times off or an unreasonable amount of counts off". With the PyOTP library I don't see a way for me to control that:
verify(otp: str, counter: int) → bool[source]
Verifies the OTP passed in against the current counter OTP.
Parameters:
otp – the OTP to check against
counter – the OTP HMAC counter
So I mean I could test it against a certain range of counters from the counter I know and then accept it if it falls within that window, but you still are either running a different application or an app on your phone to enter this code. I'm not sure exactly why I would ever use this over TOTP, but it definitely doesn't seem easier to recover from.
So TOTP would work with the recovery code but this seems aggressive to ask a normal people to install a different program on their computer or phone in order to login based on a time-based code which will stop working if the client and server (who have zero way to sync time with each other) drift too far apart. Then I need to give you recovery codes and just sorta hope you have somewhere good to put those.
That said, it is the closest to solving the problem because those are at least normal understandable human problems and it does meet my initial requirement of "the user has one good password". It's also portable and allows administrators to be like "well you fell through the one safety net, account is locked, make a new one".
What is the expected treatment of the TOTP secret?
When I was writing this out I became unsure if I'm allowed to hash this secret. Like in theory I should be able to, because I don't need to recover it. If the user was to go through a TOTP reset flow, then I would probably (presumably) want to generate a new secret in which case there's nothing stopping me from using a strong key derivation function.
None of the tutorials I was able to find seemed to have any opinion on this topic. It seems like using encryption is the SOP, which is fine (it's not sitting on disk as a plain string) but introduces another failure point. It seems odd there isn't a way to negotiate a rotation with a client or really provide any sort of feedback. It meets my initial requirement, but the more I read about TOTP the more surprised I was it hasn't been better thought out.
Things I would love from TOTP/HOTP
Some sort of secret rotation process would be great. It doesn't have to be common, but it would be nice if there was some standard way of informing the client.
Be great if we more clearly explained to people how long the codes should be valid for. Certainly 1 hour is sufficient for consumer-level applications right?
Explain like what would I do if the counters get off with HOTP. Certainly some human error must be accounted for by the designers. People are going to hit the button too many times at some point.
Use Google/Facebook/Apple
I'm not against using these sorts of login buttons except I can't offer just one, I need to offer all of them. I have no idea what login that user is going to have or what make sense for them to use. It also means I need to manage some sort of app registration with each one of these companies for each domain that they can suspend approximately whenever they feel like it because they're giant megacorps.
So now I can't just spin up as many copies of this thing as I want with different URLs and I need to go through and test each one to ensure they work. I also need to come up with some sort of migration path for if one of them disappears and I need to authenticate the users into their existing accounts but using a different source of truth.
Since I cannot think of a way to do that which doesn't involve me basically emailing a magic link to the email address I get sent in the response from your corpo login and then allowing that form to update your user account with a different "real_user_id" I gotta abandon this. It just seems like a tremendous amount of work to not really "solve" the problem but just make the problem someone else's fault if it doesn't work.
Like if a user could previously log into a Facebook account and now no longer can, there's no customer service escalation they can go on. They can effectively go fuck themselves because nobody cares about one user encountering a problem. But that means you would still need some way of being like "you were a Facebook user and now you are a Google user". Or what if the user typically logs in with Google, clicks Facebook instead and now has two accounts? Am I expected to reconcile the two?
It's also important to note that I don't want any permissions and I don't want all the information I get back. I don't want to store email address or real name or anything like that, so again like the OAuth flow is overkill for my usage. I have no intention of requesting permissions on behalf of these users with any of these providers.
Use Passkeys
Me and passkeys don't get along super well, mostly because I think they're insane. I've written a lot about them in the past: https://matduggan.com/passkeys-as-a-tool-for-user-retention/ and I won't dwell on it except to say I don't think passkeys are designed with the first goal being an easy user experience.
But regardless passkeys do solve some of my problems.
Since I'm getting a public key I don't care if my database gets leaked
In theory I don't need an email address for fallback because on some platforms some of the time they sync
If users care a lot about ownership of personal data they can use a password manager sometimes if the password manager knows the right people and idk is friends with the mayor of passkeys or something. I don't really understand how that works, like what qualifies you to store the passkeys.
Mayor of passkeys
My issue with passkeys is I cannot conceive of a even "somewhat ok" fallback plan. So you set it up on an iPhone with a Windows computer at home. You break your iPhone and get an Android. It doesn't seem that crazy of a scenario to me to not have any solution for. Do I need your phone number on top of all of this? I don't want that crap sitting in a database.
Tell the users to buy a cross-platform password manager
Oh ok yeah absolutely normal people care enough about passwords to pay a monthly fee. Thanks for the awesome tip. I think everyone on Earth would agree they'd give up most of the price of a streaming platform full of fun content to pay for a password manager. Maybe I should tell them to spin up a docker container and run bitwarden while we're at it.
Anyway I have a hyper-secure biometric login as step 1 and then what is step 2, as the fallback? An email magic link? Based on what? Do I give you "recovery codes" like I did with TOTP? It seems crazy to layer TOTP on top of passkeys but maybe that...makes some sense as a fallback route? That seems way too secure but also possibly the right answer?
I'm not even trying to be snarky, I just don't understand what would be the acceptable position to take here.
What to do from here
Basically I'm left where I started. Here are my options:
Let the user assign a username and password and hope they let the browser or password manager do it and assume it is a good one.
Use the API in the browser to generate a good username and password and store it, hoping they always use a supported browser and that this API doesn't go away in the future.
Generate a TOTP but then also give them passwords called "recovery codes" and then hope they store those passwords somewhere good.
Use email magic links a lot and hope they remember to change their email address here when they lose access to an old email.
Use passkeys and then add on one of the other recovery systems and sort of hope for the best.
What basic stuff would I need to solve this problem forever:
The browser could tell me if it generated the password or if the user typed the password. If they type the password, force the 2FA flow. If not, don't. Let me tell the user "seriously let the system make the password". 1 good password criteria met.
Have the PasswordCredential API work everywhere all the time and I'll make a random username and password on the client and then we can just be done with this forever.
Passkeys but they live in the browser and sync like a normal password. Passkey lite. Passkey but not for nuclear secrets.
TOTP but if recovery codes are gonna be a requirement can we make it part of the spec? It seems like a made-up concept we sorta tacked on top.
I don't think these are crazy requirements. I just think if we want people to build more stuff and for that stuff to be secure, someone needs to sit down and realistically map out "how does a normal person do this". We need consistent reliable conventions I can build on top of, not weird design patterns we came up with because the initial concept was never tested on normal people before being formalized into a spec.
A lot has been written in the last few weeks about the state of IT security in the aftermath of the CrowdStrike outage. A range of opinions have emerged, ranging from blaming Microsoft for signing the CrowdStrike software (who in turn blame the EU for making them do it) to blaming the companies themselves for allowing all of these machines access to the Internet to receive the automatic template update. Bike-shedding among the technical community continues to be focused on the underlying technical deployment, which misses the forest for the trees.
The better question is what was the forcing mechanism that convinced every corporation in the world that it was a good idea to install software like this on every single machine? Why is there such a cottage industry of companies that are effectively undermining Operating System security with the argument that they are doing more "advanced" security features and allowing (often unqualified) security and IT departments to make fundamental changes to things like TLS encryption and basic OS functionality? How did all these smart people let a random company push updates to everyone on Earth with zero control? The justification often give is "to pass the audit".
These audits and certifications, of which there are many, are a fundamentally broken practice. The intent of the frameworks was good, allowing for the standardization of good cybersecurity practices while not relying on the expertise of an actual cybersecurity expert to validate the results. We can all acknowledge there aren't enough of those people on Earth to actually audit all the places that need to be audited. The issue is the audits don't actually fix real problems, but instead create busywork for people so it looks like they are fixing problems. It lets people cosplay as security experts without needing to actually understand what the stuff is.
I don't come to this analysis lightly. Between HIPAA, PCI, GDPR, ISO27001 and SOC2 I've seen every possible attempt to boil requirements down to a checklist that you can do. Add in the variations on these that large companies like to send out when you are attempting to sell them an enterprise SaaS and it wouldn't surprise me at all to learn that I've spent over 10,000 hours answering and implementing solutions to meet the arbitrary requirements of these documents. I have both produced the hundred page PDFs full of impressive-looking screenshots and diagrams AND received the PDFs full of diagrams and screenshots. I've been on many calls where it is clear neither of us understands what the other is talking about, but we agree that it sounds necessary and good.
I have also been there in the room when inept IT and Security teams use these regulations, or more specifically their interpretation of these regulations, to justify kicking off expensive and unnecessary projects. I've seen laptops crippled due to full filesystem scans looking for leaked AWS credentials and Social Security numbers, even if the employee has nothing to do with that sort of data. I've watched as TLS encryption is broken with proxies so that millions of files can be generated and stored inside of S3 for security teams to never ever look at again. Even I have had to reboot my laptop to apply a non-critical OS update in the middle of an important call. All this inflicted on poor people who had to work up the enthusiasm to even show up to their stupid jobs today.
Why?
Why does this keep happening? How is it that every large company keeps falling into the same trap of repeating the same expensive, bullshit processes?
The actual steps to improve cybersecurity are hard and involve making executives mad. You need to update your software, including planning ahead for end of life technology. Since this dark art is apparently impossible to do and would involve a lot of downtime to patch known-broken shit and reboot it, we won't do that. Better apparently to lose the entire Earths personal data.
Everyone is terrified that there might be a government regulation with actual consequences if they don't have an industry solution to this problem that sounds impressive but has no real punishments. If Comcast executives could go to jail for knowingly running out-of-date Citrix NetScaler software, it would have been fixed. So instead we need impressive-sounding things which can be held up as evidence of compliance that if, ultimately, don't end up preventing leaks the consequences are minor.
Nobody questions the justification of "we need to do x because of our certification". The actual requirements are too boring to read so it becomes this blank check that can be used to roll out nearly anything.
Easier to complete a million nonsense steps than it is to get in contact with someone who understands why the steps are nonsense. The number of times I've turned on silly "security settings" to pass an audit when the settings weren't applicable to how we used the product is almost too high to count.
Most Security teams aren't capable of stopping a dedicated attacker and, in their souls, know that to be true. Especially with large organizations, the number of conceivable attack vectors becomes too painful to even think about. Therefore too much faith is placed in companies like Zscaler and CloudStrike to use "machine learning and AI" (read: magic) to close up all the possible exploits before they happen.
If your IT department works exclusively with Windows and spends their time working with GPOs and Powershell, every problem you hand them will be solved with Windows. If you handed the same problem to a Linux person, you'd get a Linux solution. People just use what they know. So you end up with a one-size-fits-all approach to problems. Like mice in a maze where almost every step is electrified, if Windows loaded up with bullshit is what they are allowed to deploy without hassles that is what you are going to get.
Future
We all know this crap doesn't work and the sooner we can stop pretending it makes a difference, the better. AT&T had every certification on the planet and still didn't take the incredibly basic step of enforcing 2FA on a database of all the most sensitive data it has in the world. If following these stupid checklists and purchasing the required software ended up with more secure platforms, I'd say "well at least there is a payoff". But time after time we see the exact same thing which is an audit is not an adequate replacement for someone who knows what they are doing looking at your stack and asking hard questions about your process. These audits aren't resulting in organizations doing the hard but necessary step of taking downtime to patch critical flaws or even applying basic security settings across all of their platforms.
Because cryptocurrency now allows for hacking groups to demand millions of dollars in payments (thanks crypto!), the financial incentives to cripple critical infrastructure have never been better. At the same time most regulations designed to encourage the right behavior are completely toothless. Asking the tech industry to regulate itself has failed, without question. All that does is generate a lot of pain and suffering for their employees, who most businesses agree are disposable and idiots. All this while doing nothing to secure personal data. Even in organizations that had smart security people asking hard questions, that advice is entirely optional. There is no stick with cybersecurity and businesses, especially now that almost all of them have made giant mistakes.
I don't know what the solution is, but I know this song and dance isn't working. The world would be better off if organizations stopped wasting so much time and money on these vendor solutions and instead stuck to much more basic solutions. Perhaps if we could just start with "have we patched all the critical CVEs in our organization" and "did we remove the shared username and password from the cloud database with millions of call records", then perhaps AFTER all the actual work is done we can have some fun and inject dangerous software into the most critical parts of our employees devices.